

commit
270745b62c
165 changed files with 2600153 additions and 0 deletions
Unified View
Diff Options
-
BINVideos/crossword-2020-08-05_17.53.58.mp4
-
BINVideos/degrees.mp4
-
BINVideos/heredity-2020-06-27_11.10.40.mp4
-
BINVideos/knights-2020-06-27_10.42.25.mp4
-
BINVideos/minesweeper-2020-06-27_10.50.43.mp4
-
BINVideos/nim-2020-08-18_10.53.43.mp4
-
BINVideos/pagerank-2020-06-27_11.01.34.mp4
-
BINVideos/parser-2020-09-01_00.16.03.mp4
-
BINVideos/questions-2020-09-01_00.26.04.mp4
-
BINVideos/shopping-2020-08-18_10.48.54.mp4
-
BINVideos/tictactoe-2020-06-17_22.09.12.mp4
-
BINVideos/traffic-2020-08-18_10.57.16.mp4
-
+74 -0crossword/.gitignore
-
+8 -0crossword/.idea/.gitignore
-
+9 -0crossword/.idea/crossword.iml
-
+9 -0crossword/.idea/misc.xml
-
+8 -0crossword/.idea/modules.xml
-
+6 -0crossword/.idea/vcs.xml
-
BINcrossword/__pycache__/crossword.cpython-38.pyc
-
BINcrossword/assets/fonts/OpenSans-Regular.ttf
-
+133 -0crossword/crossword.py
-
+5 -0crossword/data/structure0.txt
-
+9 -0crossword/data/structure1.txt
-
+6 -0crossword/data/structure2.txt
-
+10 -0crossword/data/words0.txt
-
+51 -0crossword/data/words1.txt
-
+3000 -0crossword/data/words2.txt
-
+22 -0crossword/debug.py
-
+299 -0crossword/generate.py
-
BINcrossword/images/0_0.png
-
BINcrossword/images/0_1.png
-
BINcrossword/images/0_2.png
-
BINcrossword/images/1_1.png
-
BINcrossword/images/2_2.png
-
BINcrossword/out.png
-
+9 -0crossword/video.py
-
+74 -0degrees/.gitignore
-
+8 -0degrees/.idea/.gitignore
-
+9 -0degrees/.idea/degrees.iml
-
+9 -0degrees/.idea/misc.xml
-
+8 -0degrees/.idea/modules.xml
-
+9 -0degrees/.idea/tictactoe.iml
-
+6 -0degrees/.idea/vcs.xml
-
+1 -0degrees/README.md
-
BINdegrees/__pycache__/util.cpython-38.pyc
-
+146 -0degrees/degrees.py
-
+344277 -0degrees/large/movies.csv
-
+1044500 -0degrees/large/people.csv
-
+1189595 -0degrees/large/stars.csv
-
+6 -0degrees/small/movies.csv
-
+17 -0degrees/small/people.csv
-
+21 -0degrees/small/stars.csv
-
+47 -0degrees/util.py
-
+8 -0heredity/.idea/.gitignore
-
+9 -0heredity/.idea/heredity.iml
-
+9 -0heredity/.idea/misc.xml
-
+8 -0heredity/.idea/modules.xml
-
+4 -0heredity/data/family0.csv
-
+7 -0heredity/data/family1.csv
-
+6 -0heredity/data/family2.csv
-
+212 -0heredity/heredity.py
-
+0 -0heredity/stale_outputs_checked
-
+8 -0knights/.idea/.gitignore
-
+9 -0knights/.idea/knights.iml
-
+9 -0knights/.idea/misc.xml
-
+8 -0knights/.idea/modules.xml
-
BINknights/__pycache__/logic.cpython-38.pyc
-
+263 -0knights/logic.py
-
+76 -0knights/puzzle.py
-
+8 -0minesweeper/.idea/.gitignore
-
+15 -0minesweeper/.idea/minesweeper.iml
-
+9 -0minesweeper/.idea/misc.xml
-
+8 -0minesweeper/.idea/modules.xml
-
BINminesweeper/__pycache__/minesweeper.cpython-38.pyc
-
BINminesweeper/assets/fonts/OpenSans-Regular.ttf
-
BINminesweeper/assets/images/flag.png
-
BINminesweeper/assets/images/mine.png
-
+253 -0minesweeper/minesweeper.py
-
+1 -0minesweeper/requirements.txt
-
+222 -0minesweeper/runner.py
-
+8 -0nim/.idea/.gitignore
-
+9 -0nim/.idea/misc.xml
-
+8 -0nim/.idea/modules.xml
-
+9 -0nim/.idea/nim.iml
-
BINnim/__pycache__/nim.cpython-38.pyc
-
+302 -0nim/nim.py
-
+4 -0nim/play.py
-
+8 -0pagerank/.idea/.gitignore
-
+8 -0pagerank/.idea/dictionaries/yigit.xml
-
+9 -0pagerank/.idea/misc.xml
-
+8 -0pagerank/.idea/modules.xml
-
+6 -0pagerank/.idea/other.xml
-
+9 -0pagerank/.idea/pagerank.iml
-
+14 -0pagerank/corpus0/1.html
-
+15 -0pagerank/corpus0/2.html
-
+15 -0pagerank/corpus0/3.html
-
+14 -0pagerank/corpus0/4.html
-
+14 -0pagerank/corpus1/bfs.html
-
+15 -0pagerank/corpus1/dfs.html
-
+15 -0pagerank/corpus1/games.html
BIN
Videos/crossword-2020-08-05_17.53.58.mp4
View File
BIN
Videos/degrees.mp4
View File
BIN
Videos/heredity-2020-06-27_11.10.40.mp4
View File
BIN
Videos/knights-2020-06-27_10.42.25.mp4
View File
BIN
Videos/minesweeper-2020-06-27_10.50.43.mp4
View File
BIN
Videos/nim-2020-08-18_10.53.43.mp4
View File
BIN
Videos/pagerank-2020-06-27_11.01.34.mp4
View File
BIN
Videos/parser-2020-09-01_00.16.03.mp4
View File
BIN
Videos/questions-2020-09-01_00.26.04.mp4
View File
BIN
Videos/shopping-2020-08-18_10.48.54.mp4
View File
BIN
Videos/tictactoe-2020-06-17_22.09.12.mp4
View File
BIN
Videos/traffic-2020-08-18_10.57.16.mp4
View File
+ 74
- 0
crossword/.gitignore
View File
| @ -0,0 +1,74 @@ | |||||
| # Created by .ignore support plugin (hsz.mobi) | |||||
| ### JetBrains template | |||||
| # Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio, WebStorm and Rider | |||||
| # Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839 | |||||
| # User-specific stuff | |||||
| .idea/**/workspace.xml | |||||
| .idea/**/tasks.xml | |||||
| .idea/**/usage.statistics.xml | |||||
| .idea/**/dictionaries | |||||
| .idea/**/shelf | |||||
| # Generated files | |||||
| .idea/**/contentModel.xml | |||||
| # Sensitive or high-churn files | |||||
| .idea/**/dataSources/ | |||||
| .idea/**/dataSources.ids | |||||
| .idea/**/dataSources.local.xml | |||||
| .idea/**/sqlDataSources.xml | |||||
| .idea/**/dynamic.xml | |||||
| .idea/**/uiDesigner.xml | |||||
| .idea/**/dbnavigator.xml | |||||
| # Gradle | |||||
| .idea/**/gradle.xml | |||||
| .idea/**/libraries | |||||
| # Gradle and Maven with auto-import | |||||
| # When using Gradle or Maven with auto-import, you should exclude module files, | |||||
| # since they will be recreated, and may cause churn. Uncomment if using | |||||
| # auto-import. | |||||
| # .idea/artifacts | |||||
| # .idea/compiler.xml | |||||
| # .idea/jarRepositories.xml | |||||
| # .idea/modules.xml | |||||
| # .idea/*.iml | |||||
| # .idea/modules | |||||
| # *.iml | |||||
| # *.ipr | |||||
| # CMake | |||||
| cmake-build-*/ | |||||
| # Mongo Explorer plugin | |||||
| .idea/**/mongoSettings.xml | |||||
| # File-based project format | |||||
| *.iws | |||||
| # IntelliJ | |||||
| out/ | |||||
| # mpeltonen/sbt-idea plugin | |||||
| .idea_modules/ | |||||
| # JIRA plugin | |||||
| atlassian-ide-plugin.xml | |||||
| # Cursive Clojure plugin | |||||
| .idea/replstate.xml | |||||
| # Crashlytics plugin (for Android Studio and IntelliJ) | |||||
| com_crashlytics_export_strings.xml | |||||
| crashlytics.properties | |||||
| crashlytics-build.properties | |||||
| fabric.properties | |||||
| # Editor-based Rest Client | |||||
| .idea/httpRequests | |||||
| # Android studio 3.1+ serialized cache file | |||||
| .idea/caches/build_file_checksums.ser | |||||
+ 8
- 0
crossword/.idea/.gitignore
View File
| @ -0,0 +1,8 @@ | |||||
| # Default ignored files | |||||
| /shelf/ | |||||
| /workspace.xml | |||||
| # Datasource local storage ignored files | |||||
| /dataSources/ | |||||
| /dataSources.local.xml | |||||
| # Editor-based HTTP Client requests | |||||
| /httpRequests/ | |||||
+ 9
- 0
crossword/.idea/crossword.iml
View File
| @ -0,0 +1,9 @@ | |||||
| <?xml version="1.0" encoding="UTF-8"?> | |||||
| <module type="JAVA_MODULE" version="4"> | |||||
| <component name="NewModuleRootManager" inherit-compiler-output="true"> | |||||
| <exclude-output /> | |||||
| <content url="file://$MODULE_DIR$" /> | |||||
| <orderEntry type="inheritedJdk" /> | |||||
| <orderEntry type="sourceFolder" forTests="false" /> | |||||
| </component> | |||||
| </module> | |||||
+ 9
- 0
crossword/.idea/misc.xml
View File
| @ -0,0 +1,9 @@ | |||||
| <?xml version="1.0" encoding="UTF-8"?> | |||||
| <project version="4"> | |||||
| <component name="JavaScriptSettings"> | |||||
| <option name="languageLevel" value="ES6" /> | |||||
| </component> | |||||
| <component name="ProjectRootManager" version="2" languageLevel="JDK_11" default="false" project-jdk-name="Python 3.8" project-jdk-type="Python SDK"> | |||||
| <output url="file://$PROJECT_DIR$/out" /> | |||||
| </component> | |||||
| </project> | |||||
+ 8
- 0
crossword/.idea/modules.xml
View File
| @ -0,0 +1,8 @@ | |||||
| <?xml version="1.0" encoding="UTF-8"?> | |||||
| <project version="4"> | |||||
| <component name="ProjectModuleManager"> | |||||
| <modules> | |||||
| <module fileurl="file://$PROJECT_DIR$/.idea/crossword.iml" filepath="$PROJECT_DIR$/.idea/crossword.iml" /> | |||||
| </modules> | |||||
| </component> | |||||
| </project> | |||||
+ 6
- 0
crossword/.idea/vcs.xml
View File
| @ -0,0 +1,6 @@ | |||||
| <?xml version="1.0" encoding="UTF-8"?> | |||||
| <project version="4"> | |||||
| <component name="VcsDirectoryMappings"> | |||||
| <mapping directory="$PROJECT_DIR$" vcs="Git" /> | |||||
| </component> | |||||
| </project> | |||||
BIN
crossword/__pycache__/crossword.cpython-38.pyc
View File
BIN
crossword/assets/fonts/OpenSans-Regular.ttf
View File
+ 133
- 0
crossword/crossword.py
View File
| @ -0,0 +1,133 @@ | |||||
| class Variable(): | |||||
| ACROSS = "across" | |||||
| DOWN = "down" | |||||
| def __init__(self, i, j, direction, length): | |||||
| """Create a new variable with starting point, direction, and length.""" | |||||
| self.i = i | |||||
| self.j = j | |||||
| self.direction = direction | |||||
| self.length = length | |||||
| self.cells = [] | |||||
| for k in range(self.length): | |||||
| self.cells.append( | |||||
| (self.i + (k if self.direction == Variable.DOWN else 0), | |||||
| self.j + (k if self.direction == Variable.ACROSS else 0)) | |||||
| ) | |||||
| def __hash__(self): | |||||
| return hash((self.i, self.j, self.direction, self.length)) | |||||
| def __eq__(self, other): | |||||
| return ( | |||||
| (self.i == other.i) and | |||||
| (self.j == other.j) and | |||||
| (self.direction == other.direction) and | |||||
| (self.length == other.length) | |||||
| ) | |||||
| def __str__(self): | |||||
| return f"({self.i}, {self.j}) {self.direction} : {self.length}" | |||||
| def __repr__(self): | |||||
| direction = repr(self.direction) | |||||
| return f"Variable({self.i}, {self.j}, {direction}, {self.length})" | |||||
| class Crossword(): | |||||
| def __init__(self, structure_file, words_file): | |||||
| # Determine structure of crossword | |||||
| with open(structure_file) as f: | |||||
| contents = f.read().splitlines() | |||||
| self.height = len(contents) | |||||
| self.width = max(len(line) for line in contents) | |||||
| self.structure = [] | |||||
| for i in range(self.height): | |||||
| row = [] | |||||
| for j in range(self.width): | |||||
| if j >= len(contents[i]): | |||||
| row.append(False) | |||||
| elif contents[i][j] == "_": | |||||
| row.append(True) | |||||
| else: | |||||
| row.append(False) | |||||
| self.structure.append(row) | |||||
| # Save vocabulary list | |||||
| with open(words_file) as f: | |||||
| self.words = set(f.read().upper().splitlines()) | |||||
| # Determine variable set | |||||
| self.variables = set() | |||||
| for i in range(self.height): | |||||
| for j in range(self.width): | |||||
| # Vertical words | |||||
| starts_word = ( | |||||
| self.structure[i][j] | |||||
| and (i == 0 or not self.structure[i - 1][j]) | |||||
| ) | |||||
| if starts_word: | |||||
| length = 1 | |||||
| for k in range(i + 1, self.height): | |||||
| if self.structure[k][j]: | |||||
| length += 1 | |||||
| else: | |||||
| break | |||||
| if length > 1: | |||||
| self.variables.add(Variable( | |||||
| i=i, j=j, | |||||
| direction=Variable.DOWN, | |||||
| length=length | |||||
| )) | |||||
| # Horizontal words | |||||
| starts_word = ( | |||||
| self.structure[i][j] | |||||
| and (j == 0 or not self.structure[i][j - 1]) | |||||
| ) | |||||
| if starts_word: | |||||
| length = 1 | |||||
| for k in range(j + 1, self.width): | |||||
| if self.structure[i][k]: | |||||
| length += 1 | |||||
| else: | |||||
| break | |||||
| if length > 1: | |||||
| self.variables.add(Variable( | |||||
| i=i, j=j, | |||||
| direction=Variable.ACROSS, | |||||
| length=length | |||||
| )) | |||||
| # Compute overlaps for each word | |||||
| # For any pair of variables v1, v2, their overlap is either: | |||||
| # None, if the two variables do not overlap; or | |||||
| # (i, j), where v1's ith character overlaps v2's jth character | |||||
| self.overlaps = dict() | |||||
| for v1 in self.variables: | |||||
| for v2 in self.variables: | |||||
| if v1 == v2: | |||||
| continue | |||||
| cells1 = v1.cells | |||||
| cells2 = v2.cells | |||||
| intersection = set(cells1).intersection(cells2) | |||||
| if not intersection: | |||||
| self.overlaps[v1, v2] = None | |||||
| else: | |||||
| intersection = intersection.pop() | |||||
| self.overlaps[v1, v2] = ( | |||||
| cells1.index(intersection), | |||||
| cells2.index(intersection) | |||||
| ) | |||||
| def neighbors(self, var): | |||||
| """Given a variable, return set of overlapping variables.""" | |||||
| return set( | |||||
| v for v in self.variables | |||||
| if v != var and self.overlaps[v, var] | |||||
| ) | |||||
+ 5
- 0
crossword/data/structure0.txt
View File
| @ -0,0 +1,5 @@ | |||||
| #___# | |||||
| #_##_ | |||||
| #_##_ | |||||
| #_##_ | |||||
| #____ | |||||
+ 9
- 0
crossword/data/structure1.txt
View File
| @ -0,0 +1,9 @@ | |||||
| ############## | |||||
| #######_####_# | |||||
| #____________# | |||||
| #_#####_####_# | |||||
| #_##_____###_# | |||||
| #_#####_####_# | |||||
| #_###______#_# | |||||
| #######_####_# | |||||
| ############## | |||||
+ 6
- 0
crossword/data/structure2.txt
View File
| @ -0,0 +1,6 @@ | |||||
| ######_ | |||||
| ____##_ | |||||
| _##____ | |||||
| _##_##_ | |||||
| _##_##_ | |||||
| #___##_ | |||||
+ 10
- 0
crossword/data/words0.txt
View File
| @ -0,0 +1,10 @@ | |||||
| one | |||||
| two | |||||
| three | |||||
| four | |||||
| five | |||||
| six | |||||
| seven | |||||
| eight | |||||
| nine | |||||
| ten | |||||
+ 51
- 0
crossword/data/words1.txt
View File
| @ -0,0 +1,51 @@ | |||||
| adversarial | |||||
| alpha | |||||
| arc | |||||
| artificial | |||||
| bayes | |||||
| beta | |||||
| bit | |||||
| breadth | |||||
| byte | |||||
| classification | |||||
| classify | |||||
| condition | |||||
| constraint | |||||
| create | |||||
| depth | |||||
| distribution | |||||
| end | |||||
| false | |||||
| graph | |||||
| heuristic | |||||
| infer | |||||
| inference | |||||
| initial | |||||
| intelligence | |||||
| knowledge | |||||
| language | |||||
| learning | |||||
| line | |||||
| logic | |||||
| loss | |||||
| markov | |||||
| minimax | |||||
| network | |||||
| neural | |||||
| node | |||||
| optimization | |||||
| probability | |||||
| proposition | |||||
| prune | |||||
| reason | |||||
| recurrent | |||||
| regression | |||||
| resolution | |||||
| resolve | |||||
| satisfaction | |||||
| search | |||||
| sine | |||||
| start | |||||
| true | |||||
| truth | |||||
| uncertainty | |||||
+ 3000
- 0
crossword/data/words2.txt
File diff suppressed because it is too large
View File
+ 22
- 0
crossword/debug.py
View File
| @ -0,0 +1,22 @@ | |||||
| import os | |||||
| import sys | |||||
| import time | |||||
| import subprocess | |||||
| combinations = [(0, 0), (0, 1),(1, 1),(2, 2),(1, 2),(0, 2)] | |||||
| start = time.time() | |||||
| for count in range(int(sys.argv[1])): | |||||
| print("RUN " + str(count + 1)) | |||||
| for i in combinations: | |||||
| os.system("python generate.py data/structure{0}.txt data/words{1}.txt > debug/{0}_{1}.{2}.out".format(i[0], i[1], count)) | |||||
| print("Program took {} seconds to execute on average".format((time.time()-start) / (count + 1))) | |||||
| proc = subprocess.Popen(["grep 'No solution' debug/*"], stdout=subprocess.PIPE, shell=True) | |||||
| (out, err) = proc.communicate() | |||||
| out = out.decode() | |||||
| print("{} tests did not find any solutions!\n".format(len(out.split("\n")) - 1)) | |||||
| for i in out.split("\n"): | |||||
| print(i.split(":")[0]) | |||||
+ 299
- 0
crossword/generate.py
View File
| @ -0,0 +1,299 @@ | |||||
| import sys | |||||
| from copy import deepcopy | |||||
| from crossword import * | |||||
| # I did this project during vacation with a bunch of kids screaming around me, so it is | |||||
| # very possible that some parts of the code is sub-optimal and not particularly pretty | |||||
| # I do not accept any responsibility if you suffer brain damage or have an | |||||
| # aneurysm while reading the code below | |||||
| class CrosswordCreator(): | |||||
| def __init__(self, crossword): | |||||
| """ | |||||
| Create new CSP crossword generate. | |||||
| """ | |||||
| self.crossword = crossword | |||||
| self.domains = { | |||||
| var: self.crossword.words.copy() | |||||
| for var in self.crossword.variables | |||||
| } | |||||
| def letter_grid(self, assignment): | |||||
| """ | |||||
| Return 2D array representing a given assignment. | |||||
| """ | |||||
| letters = [ | |||||
| [None for _ in range(self.crossword.width)] | |||||
| for _ in range(self.crossword.height) | |||||
| ] | |||||
| for variable, word in assignment.items(): | |||||
| direction = variable.direction | |||||
| for k in range(len(word)): | |||||
| i = variable.i + (k if direction == Variable.DOWN else 0) | |||||
| j = variable.j + (k if direction == Variable.ACROSS else 0) | |||||
| letters[i][j] = word[k] | |||||
| return letters | |||||
| def print(self, assignment): | |||||
| """ | |||||
| Print crossword assignment to the terminal. | |||||
| """ | |||||
| letters = self.letter_grid(assignment) | |||||
| print() | |||||
| print("_"*self.crossword.width*2) | |||||
| for i in range(self.crossword.height): | |||||
| for j in range(self.crossword.width): | |||||
| if self.crossword.structure[i][j]: | |||||
| print(letters[i][j] or " ", end="|") | |||||
| else: | |||||
| print("■", end="|") | |||||
| print() | |||||
| print("-"*self.crossword.width*2) | |||||
| def save(self, assignment, filename): | |||||
| """ | |||||
| Save crossword assignment to an image file. | |||||
| """ | |||||
| from PIL import Image, ImageDraw, ImageFont | |||||
| cell_size = 100 | |||||
| cell_border = 2 | |||||
| interior_size = cell_size - 2 * cell_border | |||||
| letters = self.letter_grid(assignment) | |||||
| # Create a blank canvas | |||||
| img = Image.new( | |||||
| "RGBA", | |||||
| (self.crossword.width * cell_size, | |||||
| self.crossword.height * cell_size), | |||||
| "black" | |||||
| ) | |||||
| font = ImageFont.truetype("assets/fonts/OpenSans-Regular.ttf", 80) | |||||
| draw = ImageDraw.Draw(img) | |||||
| for i in range(self.crossword.height): | |||||
| for j in range(self.crossword.width): | |||||
| rect = [ | |||||
| (j * cell_size + cell_border, | |||||
| i * cell_size + cell_border), | |||||
| ((j + 1) * cell_size - cell_border, | |||||
| (i + 1) * cell_size - cell_border) | |||||
| ] | |||||
| if self.crossword.structure[i][j]: | |||||
| draw.rectangle(rect, fill="white") | |||||
| if letters[i][j]: | |||||
| w, h = draw.textsize(letters[i][j], font=font) | |||||
| draw.text( | |||||
| (rect[0][0] + ((interior_size - w) / 2), | |||||
| rect[0][1] + ((interior_size - h) / 2) - 10), | |||||
| letters[i][j], fill="black", font=font | |||||
| ) | |||||
| img.save(filename) | |||||
| def solve(self): | |||||
| """ | |||||
| Enforce node and arc consistency, and then solve the CSP. | |||||
| """ | |||||
| self.enforce_node_consistency() | |||||
| self.ac3() | |||||
| return self.backtrack(dict()) | |||||
| def enforce_node_consistency(self): | |||||
| """ | |||||
| Update `self.domains` such that each variable is node-consistent. | |||||
| (Remove any values that are inconsistent with a variable's unary | |||||
| constraints; in this case, the length of the word.) | |||||
| """ | |||||
| for var in self.domains: | |||||
| new_domain = self.domains[var].copy() | |||||
| for word in self.domains[var]: | |||||
| if var.length != len(word): | |||||
| new_domain -= {word} | |||||
| self.domains[var] = new_domain | |||||
| def revise(self, x, y): | |||||
| revised = False | |||||
| def search_in_domain(domain, index, char, disallow): | |||||
| for word in domain: | |||||
| if word[index] == char and word != disallow: | |||||
| return True | |||||
| return False | |||||
| if (x, y) in self.crossword.overlaps: | |||||
| new_domain = self.domains[x].copy() | |||||
| overlap = self.crossword.overlaps[(x, y)] | |||||
| for i in self.domains[x]: | |||||
| if not search_in_domain(self.domains[y], overlap[1], i[overlap[0]], i): | |||||
| new_domain -= {i} | |||||
| revised = True | |||||
| self.domains[x] = new_domain | |||||
| return revised | |||||
| def ac3(self, arcs=None): | |||||
| if arcs: | |||||
| queue = arcs | |||||
| else: | |||||
| queue = [] | |||||
| for i in self.crossword.overlaps: | |||||
| if self.crossword.overlaps[i]: | |||||
| queue.append(i) | |||||
| while queue: | |||||
| (x, y) = queue[-1] | |||||
| queue = queue[:-1] | |||||
| if self.revise(x, y): | |||||
| if len(self.domains[x]) == 0: | |||||
| return False | |||||
| for i in self.crossword.neighbors(x) - {y}: | |||||
| queue.append((i, x)) | |||||
| return True | |||||
| def assignment_complete(self, assignment): | |||||
| """ | |||||
| Return True if `assignment` is complete (i.e., assigns a value to each | |||||
| crossword variable); return False otherwise. | |||||
| """ | |||||
| return len(assignment) == len(self.domains) | |||||
| def consistent(self, assignment): | |||||
| """ | |||||
| Return True if `assignment` is consistent (i.e., words fit in crossword | |||||
| puzzle without conflicting characters); return False otherwise. | |||||
| """ | |||||
| if not assignment: | |||||
| return False | |||||
| for i in assignment: | |||||
| if i.length != len(assignment[i]): | |||||
| return False | |||||
| for j in assignment: | |||||
| if j == i: | |||||
| continue | |||||
| overlap = self.crossword.overlaps[(i, j)] | |||||
| if overlap: | |||||
| if assignment[i][overlap[0]] != assignment[j][overlap[1]]: | |||||
| return False | |||||
| return True | |||||
| def order_domain_values(self, var, assignment): | |||||
| """ | |||||
| Return a list of values in the domain of `var`, in order by | |||||
| the number of values they rule out for neighboring variables. | |||||
| The first value in the list, for example, should be the one | |||||
| that rules out the fewest values among the neighbors of `var`. | |||||
| """ | |||||
| domain = [] | |||||
| for i in self.domains[var]: | |||||
| discarded = 0 | |||||
| for j in self.crossword.neighbors(var): | |||||
| if j not in assignment: | |||||
| overlap = self.crossword.overlaps[(var, j)] | |||||
| for k in self.domains[j]: | |||||
| if k[overlap[1]] != i[overlap[0]]: | |||||
| discarded += 1 | |||||
| domain.append((discarded, i)) | |||||
| domain.sort(key = lambda x: x[0]) | |||||
| final = [] | |||||
| for i in domain: | |||||
| final.append(i[1]) | |||||
| return final | |||||
| def select_unassigned_variable(self, assignment): | |||||
| """ | |||||
| Return an unassigned variable not already part of `assignment`. | |||||
| Choose the variable with the minimum number of remaining values | |||||
| in its domain. If there is a tie, choose the variable with the highest | |||||
| degree. If there is a tie, any of the tied variables are acceptable | |||||
| return values. | |||||
| """ | |||||
| best = [len(self.crossword.words) + 1, 0, []] | |||||
| for i in self.domains: | |||||
| if i not in assignment: | |||||
| length = self.domains[i].__len__() | |||||
| if best[0] > length: | |||||
| neighbors = self.crossword.neighbors(i) | |||||
| best[0] = length | |||||
| best[2].append(i) | |||||
| best[1] = len(neighbors) | |||||
| elif best[0] == length: | |||||
| neighbors = self.crossword.neighbors(i) | |||||
| if len(neighbors) == best[1]: | |||||
| best[2].append(self.domains[i]) | |||||
| elif len(neighbors) < best[1]: | |||||
| best[2] = [i] | |||||
| best[1] = len(neighbors) | |||||
| return best[2][0] | |||||
| def backtrack(self, assignment): | |||||
| """ | |||||
| Using Backtracking Search, take as input a partial assignment for the | |||||
| crossword and return a complete assignment if possible to do so. | |||||
| `assignment` is a mapping from variables (keys) to words (values). | |||||
| If no assignment is possible, return None. | |||||
| """ | |||||
| if self.assignment_complete(assignment): | |||||
| return assignment | |||||
| var = self.select_unassigned_variable(assignment) | |||||
| domain_values = self.order_domain_values(var, assignment) | |||||
| inferences = [] | |||||
| domains_backup = deepcopy(self.domains) | |||||
| for i in domain_values: | |||||
| assignment[var] = i | |||||
| arcs = [] | |||||
| self.domains[var] = {i} | |||||
| for j in self.crossword.neighbors(var): | |||||
| arcs.append(self.crossword.overlaps[(j, var)]) | |||||
| if not self.ac3(arcs=arcs): | |||||
| continue | |||||
| inferences = self.infer(assignment) | |||||
| if self.consistent(assignment): | |||||
| result = self.backtrack(assignment) | |||||
| if result: | |||||
| return result | |||||
| for j in inferences: | |||||
| assignment.pop(j) | |||||
| assignment.pop(var) | |||||
| self.domains = domains_backup | |||||
| return None | |||||
| def infer(self, assignment): | |||||
| inferred = [] | |||||
| for i in self.domains: | |||||
| if i in assignment: | |||||
| continue | |||||
| val = self.domains[i] | |||||
| if len(val) == 1: | |||||
| inferred.append(i) | |||||
| assignment[i] = next(iter(val)) | |||||
| return inferred | |||||
| def main(): | |||||
| # Check usage | |||||
| if len(sys.argv) not in [3, 4]: | |||||
| sys.exit("Usage: python generate.py structure words [output]") | |||||
| # Parse command-line arguments | |||||
| structure = sys.argv[1] | |||||
| words = sys.argv[2] | |||||
| output = sys.argv[3] if len(sys.argv) == 4 else None | |||||
| # Generate crossword | |||||
| crossword = Crossword(structure, words) | |||||
| creator = CrosswordCreator(crossword) | |||||
| assignment = creator.solve() | |||||
| # Print result | |||||
| if assignment is None: | |||||
| print("No solution.") | |||||
| else: | |||||
| creator.print(assignment) | |||||
| if output: | |||||
| creator.save(assignment, output) | |||||
| if __name__ == "__main__": | |||||
| main() | |||||
BIN
crossword/images/0_0.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 500 | Height: 500 | Size: 11 KiB |
BIN
crossword/images/0_1.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 500 | Height: 500 | Size: 12 KiB |
BIN
crossword/images/0_2.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 500 | Height: 500 | Size: 14 KiB |
BIN
crossword/images/1_1.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 1400 | Height: 900 | Size: 41 KiB |
BIN
crossword/images/2_2.png
View File
{kind=link}
| Before | After |
|---|---|
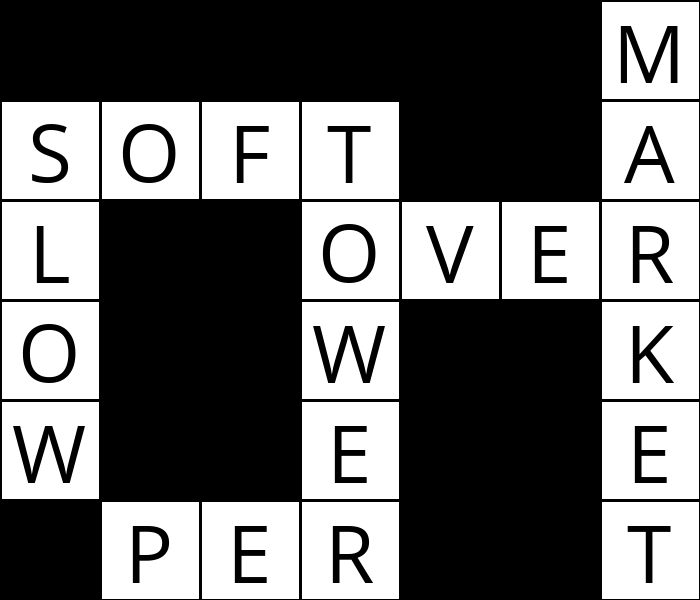
|
|
| Width: 700 | Height: 600 | Size: 27 KiB |
BIN
crossword/out.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 1400 | Height: 900 | Size: 41 KiB |
+ 9
- 0
crossword/video.py
View File
| @ -0,0 +1,9 @@ | |||||
| import os | |||||
| import time | |||||
| combinations = [(0,0),(0,1),(1,1),(2,2),(0,2)] | |||||
| for i in combinations: | |||||
| print("Running structure {} with words {}".format(i[0], i[1])) | |||||
| os.system("python generate.py data/structure{0}.txt data/words{1}.txt images/{0}_{1}.png".format(i[0], i[1])) | |||||
| time.sleep(0.5) | |||||
+ 74
- 0
degrees/.gitignore
View File
| @ -0,0 +1,74 @@ | |||||
| # Created by .ignore support plugin (hsz.mobi) | |||||
| ### JetBrains template | |||||
| # Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio, WebStorm and Rider | |||||
| # Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839 | |||||
| # User-specific stuff | |||||
| .idea/**/workspace.xml | |||||
| .idea/**/tasks.xml | |||||
| .idea/**/usage.statistics.xml | |||||
| .idea/**/dictionaries | |||||
| .idea/**/shelf | |||||
| # Generated files | |||||
| .idea/**/contentModel.xml | |||||
| # Sensitive or high-churn files | |||||
| .idea/**/dataSources/ | |||||
| .idea/**/dataSources.ids | |||||
| .idea/**/dataSources.local.xml | |||||
| .idea/**/sqlDataSources.xml | |||||
| .idea/**/dynamic.xml | |||||
| .idea/**/uiDesigner.xml | |||||
| .idea/**/dbnavigator.xml | |||||
| # Gradle | |||||
| .idea/**/gradle.xml | |||||
| .idea/**/libraries | |||||
| # Gradle and Maven with auto-import | |||||
| # When using Gradle or Maven with auto-import, you should exclude module files, | |||||
| # since they will be recreated, and may cause churn. Uncomment if using | |||||
| # auto-import. | |||||
| # .idea/artifacts | |||||
| # .idea/compiler.xml | |||||
| # .idea/jarRepositories.xml | |||||
| # .idea/modules.xml | |||||
| # .idea/*.iml | |||||
| # .idea/modules | |||||
| # *.iml | |||||
| # *.ipr | |||||
| # CMake | |||||
| cmake-build-*/ | |||||
| # Mongo Explorer plugin | |||||
| .idea/**/mongoSettings.xml | |||||
| # File-based project format | |||||
| *.iws | |||||
| # IntelliJ | |||||
| out/ | |||||
| # mpeltonen/sbt-idea plugin | |||||
| .idea_modules/ | |||||
| # JIRA plugin | |||||
| atlassian-ide-plugin.xml | |||||
| # Cursive Clojure plugin | |||||
| .idea/replstate.xml | |||||
| # Crashlytics plugin (for Android Studio and IntelliJ) | |||||
| com_crashlytics_export_strings.xml | |||||
| crashlytics.properties | |||||
| crashlytics-build.properties | |||||
| fabric.properties | |||||
| # Editor-based Rest Client | |||||
| .idea/httpRequests | |||||
| # Android studio 3.1+ serialized cache file | |||||
| .idea/caches/build_file_checksums.ser | |||||
+ 8
- 0
degrees/.idea/.gitignore
View File
| @ -0,0 +1,8 @@ | |||||
| # Default ignored files | |||||
| /shelf/ | |||||
| /workspace.xml | |||||
| # Datasource local storage ignored files | |||||
| /dataSources/ | |||||
| /dataSources.local.xml | |||||
| # Editor-based HTTP Client requests | |||||
| /httpRequests/ | |||||
+ 9
- 0
degrees/.idea/degrees.iml
View File
| @ -0,0 +1,9 @@ | |||||
| <?xml version="1.0" encoding="UTF-8"?> | |||||
| <module type="JAVA_MODULE" version="4"> | |||||
| <component name="NewModuleRootManager" inherit-compiler-output="true"> | |||||
| <exclude-output /> | |||||
| <content url="file://$MODULE_DIR$" /> | |||||
| <orderEntry type="inheritedJdk" /> | |||||
| <orderEntry type="sourceFolder" forTests="false" /> | |||||
| </component> | |||||
| </module> | |||||
+ 9
- 0
degrees/.idea/misc.xml
View File
| @ -0,0 +1,9 @@ | |||||
| <?xml version="1.0" encoding="UTF-8"?> | |||||
| <project version="4"> | |||||
| <component name="JavaScriptSettings"> | |||||
| <option name="languageLevel" value="ES6" /> | |||||
| </component> | |||||
| <component name="ProjectRootManager" version="2" languageLevel="JDK_11" default="false" project-jdk-name="Python 3.8" project-jdk-type="Python SDK"> | |||||
| <output url="file://$PROJECT_DIR$/out" /> | |||||
| </component> | |||||
| </project> | |||||
+ 8
- 0
degrees/.idea/modules.xml
View File
| @ -0,0 +1,8 @@ | |||||
| <?xml version="1.0" encoding="UTF-8"?> | |||||
| <project version="4"> | |||||
| <component name="ProjectModuleManager"> | |||||
| <modules> | |||||
| <module fileurl="file://$PROJECT_DIR$/.idea/degrees.iml" filepath="$PROJECT_DIR$/.idea/degrees.iml" /> | |||||
| </modules> | |||||
| </component> | |||||
| </project> | |||||
+ 9
- 0
degrees/.idea/tictactoe.iml
View File
| @ -0,0 +1,9 @@ | |||||
| <?xml version="1.0" encoding="UTF-8"?> | |||||
| <module type="JAVA_MODULE" version="4"> | |||||
| <component name="NewModuleRootManager" inherit-compiler-output="true"> | |||||
| <exclude-output /> | |||||
| <content url="file://$MODULE_DIR$" /> | |||||
| <orderEntry type="inheritedJdk" /> | |||||
| <orderEntry type="sourceFolder" forTests="false" /> | |||||
| </component> | |||||
| </module> | |||||
+ 6
- 0
degrees/.idea/vcs.xml
View File
| @ -0,0 +1,6 @@ | |||||
| <?xml version="1.0" encoding="UTF-8"?> | |||||
| <project version="4"> | |||||
| <component name="VcsDirectoryMappings"> | |||||
| <mapping directory="$PROJECT_DIR$" vcs="Git" /> | |||||
| </component> | |||||
| </project> | |||||
+ 1
- 0
degrees/README.md
View File
| @ -0,0 +1 @@ | |||||
| # yigitcolakoglu | |||||
BIN
degrees/__pycache__/util.cpython-38.pyc
View File
+ 146
- 0
degrees/degrees.py
View File
| @ -0,0 +1,146 @@ | |||||
| import csv | |||||
| import sys | |||||
| from util import Node, StackFrontier, QueueFrontier | |||||
| # Maps names to a set of corresponding person_ids | |||||
| names = {} | |||||
| # Maps person_ids to a dictionary of: name, birth, movies (a set of movie_ids) | |||||
| people = {} | |||||
| # Maps movie_ids to a dictionary of: title, year, stars (a set of person_ids) | |||||
| movies = {} | |||||
| def load_data(directory): | |||||
| """ | |||||
| Load data from CSV files into memory. | |||||
| """ | |||||
| # Load people | |||||
| with open(f"{directory}/people.csv", encoding="utf-8") as f: | |||||
| reader = csv.DictReader(f) | |||||
| for row in reader: | |||||
| people[row["id"]] = { | |||||
| "name": row["name"], | |||||
| "birth": row["birth"], | |||||
| "movies": set() | |||||
| } | |||||
| if row["name"].lower() not in names: | |||||
| names[row["name"].lower()] = {row["id"]} | |||||
| else: | |||||
| names[row["name"].lower()].add(row["id"]) | |||||
| # Load movies | |||||
| with open(f"{directory}/movies.csv", encoding="utf-8") as f: | |||||
| reader = csv.DictReader(f) | |||||
| for row in reader: | |||||
| movies[row["id"]] = { | |||||
| "title": row["title"], | |||||
| "year": row["year"], | |||||
| "stars": set() | |||||
| } | |||||
| # Load stars | |||||
| with open(f"{directory}/stars.csv", encoding="utf-8") as f: | |||||
| reader = csv.DictReader(f) | |||||
| for row in reader: | |||||
| try: | |||||
| people[row["person_id"]]["movies"].add(row["movie_id"]) | |||||
| movies[row["movie_id"]]["stars"].add(row["person_id"]) | |||||
| except KeyError: | |||||
| pass | |||||
| def main(): | |||||
| if len(sys.argv) > 2: | |||||
| sys.exit("Usage: python degrees.py [directory]") | |||||
| directory = sys.argv[1] if len(sys.argv) == 2 else "large" | |||||
| # Load data from files into memory | |||||
| print("Loading data...") | |||||
| load_data(directory) | |||||
| print("Data loaded.") | |||||
| source = person_id_for_name(input("Name: ")) | |||||
| if source is None: | |||||
| sys.exit("Person not found.") | |||||
| target = person_id_for_name(input("Name: ")) | |||||
| if target is None: | |||||
| sys.exit("Person not found.") | |||||
| path = shortest_path(source, target) | |||||
| if path is None: | |||||
| print("Not connected.") | |||||
| else: | |||||
| degrees = len(path) | |||||
| print(f"{degrees} degrees of separation.") | |||||
| path = [(None, source)] + path | |||||
| for i in range(degrees): | |||||
| person1 = people[path[i][1]]["name"] | |||||
| person2 = people[path[i + 1][1]]["name"] | |||||
| movie = movies[path[i + 1][0]]["title"] | |||||
| print(f"{i + 1}: {person1} and {person2} starred in {movie}") | |||||
| def shortest_path(source, target): | |||||
| explored_nodes = set() | |||||
| frontier = QueueFrontier() | |||||
| frontier.add(Node(source, None, None)) | |||||
| while True: | |||||
| if frontier.empty(): | |||||
| return None | |||||
| current_node = frontier.remove() | |||||
| explored_nodes.add(current_node.state) | |||||
| for i in neighbors_for_person(current_node.state): | |||||
| actor_node = Node(i[1], current_node, i[0]) | |||||
| if actor_node.state in explored_nodes: | |||||
| continue | |||||
| if i[1] == target: | |||||
| return actor_node.draw_path() | |||||
| frontier.add(actor_node) | |||||
| def person_id_for_name(name): | |||||
| """ | |||||
| Returns the IMDB id for a person's name, | |||||
| resolving ambiguities as needed. | |||||
| """ | |||||
| person_ids = list(names.get(name.lower(), set())) | |||||
| if len(person_ids) == 0: | |||||
| return None | |||||
| elif len(person_ids) > 1: | |||||
| print(f"Which '{name}'?") | |||||
| for person_id in person_ids: | |||||
| person = people[person_id] | |||||
| name = person["name"] | |||||
| birth = person["birth"] | |||||
| print(f"ID: {person_id}, Name: {name}, Birth: {birth}") | |||||
| try: | |||||
| person_id = input("Intended Person ID: ") | |||||
| if person_id in person_ids: | |||||
| return person_id | |||||
| except ValueError: | |||||
| pass | |||||
| return None | |||||
| else: | |||||
| return person_ids[0] | |||||
| def neighbors_for_person(person_id): | |||||
| """ | |||||
| Returns (movie_id, person_id) pairs for people | |||||
| who starred with a given person. | |||||
| """ | |||||
| movie_ids = people[person_id]["movies"] | |||||
| neighbors = set() | |||||
| for movie_id in movie_ids: | |||||
| for person_id in movies[movie_id]["stars"]: | |||||
| neighbors.add((movie_id, person_id)) | |||||
| return neighbors | |||||
| if __name__ == "__main__": | |||||
| main() | |||||
+ 344277
- 0
degrees/large/movies.csv
File diff suppressed because it is too large
View File
+ 1044500
- 0
degrees/large/people.csv
File diff suppressed because it is too large
View File
+ 1189595
- 0
degrees/large/stars.csv
File diff suppressed because it is too large
View File
+ 6
- 0
degrees/small/movies.csv
View File
| @ -0,0 +1,6 @@ | |||||
| id,title,year | |||||
| 112384,"Apollo 13",1995 | |||||
| 104257,"A Few Good Men",1992 | |||||
| 109830,"Forrest Gump",1994 | |||||
| 93779,"The Princess Bride",1987 | |||||
| 95953,"Rain Man",1988 | |||||
+ 17
- 0
degrees/small/people.csv
View File
| @ -0,0 +1,17 @@ | |||||
| id,name,birth | |||||
| 102,"Kevin Bacon",1958 | |||||
| 129,"Tom Cruise",1962 | |||||
| 144,"Cary Elwes",1962 | |||||
| 158,"Tom Hanks",1956 | |||||
| 1597,"Mandy Patinkin",1952 | |||||
| 163,"Dustin Hoffman",1937 | |||||
| 1697,"Chris Sarandon",1942 | |||||
| 193,"Demi Moore",1962 | |||||
| 197,"Jack Nicholson",1937 | |||||
| 200,"Bill Paxton",1955 | |||||
| 398,"Sally Field",1946 | |||||
| 420,"Valeria Golino",1965 | |||||
| 596520,"Gerald R. Molen",1935 | |||||
| 641,"Gary Sinise",1955 | |||||
| 705,"Robin Wright",1966 | |||||
| 914612,"Emma Watson",1990 | |||||
+ 21
- 0
degrees/small/stars.csv
View File
| @ -0,0 +1,21 @@ | |||||
| person_id,movie_id | |||||
| 102,104257 | |||||
| 102,112384 | |||||
| 129,104257 | |||||
| 129,95953 | |||||
| 144,93779 | |||||
| 158,109830 | |||||
| 158,112384 | |||||
| 1597,93779 | |||||
| 163,95953 | |||||
| 1697,93779 | |||||
| 193,104257 | |||||
| 197,104257 | |||||
| 200,112384 | |||||
| 398,109830 | |||||
| 420,95953 | |||||
| 596520,95953 | |||||
| 641,109830 | |||||
| 641,112384 | |||||
| 705,109830 | |||||
| 705,93779 | |||||
+ 47
- 0
degrees/util.py
View File
| @ -0,0 +1,47 @@ | |||||
| class Node(): | |||||
| def __init__(self, state, parent, action): | |||||
| self.state = state | |||||
| self.parent = parent | |||||
| self.action = action | |||||
| def draw_path(self): | |||||
| path = [] | |||||
| node = self | |||||
| while node.parent: | |||||
| path.append((node.action, node.state)) | |||||
| node = node.parent | |||||
| path.reverse() | |||||
| return path | |||||
| class StackFrontier(): | |||||
| def __init__(self): | |||||
| self.frontier = [] | |||||
| def add(self, node): | |||||
| self.frontier.append(node) | |||||
| def contains_state(self, state): | |||||
| return any(node.state == state for node in self.frontier) | |||||
| def empty(self): | |||||
| return len(self.frontier) == 0 | |||||
| def remove(self): | |||||
| if self.empty(): | |||||
| raise Exception("empty frontier") | |||||
| else: | |||||
| node = self.frontier[-1] | |||||
| self.frontier = self.frontier[:-1] | |||||
| return node | |||||
| class QueueFrontier(StackFrontier): | |||||
| def remove(self): | |||||
| if self.empty(): | |||||
| raise Exception("empty frontier") | |||||
| else: | |||||
| node = self.frontier[0] | |||||
| self.frontier = self.frontier[1:] | |||||
| return node | |||||
+ 8
- 0
heredity/.idea/.gitignore
View File
| @ -0,0 +1,8 @@ | |||||
| # Default ignored files | |||||
| /shelf/ | |||||
| /workspace.xml | |||||
| # Datasource local storage ignored files | |||||
| /dataSources/ | |||||
| /dataSources.local.xml | |||||
| # Editor-based HTTP Client requests | |||||
| /httpRequests/ | |||||
+ 9
- 0
heredity/.idea/heredity.iml
View File
| @ -0,0 +1,9 @@ | |||||
| <?xml version="1.0" encoding="UTF-8"?> | |||||
| <module type="JAVA_MODULE" version="4"> | |||||
| <component name="NewModuleRootManager" inherit-compiler-output="true"> | |||||
| <exclude-output /> | |||||
| <content url="file://$MODULE_DIR$" /> | |||||
| <orderEntry type="inheritedJdk" /> | |||||
| <orderEntry type="sourceFolder" forTests="false" /> | |||||
| </component> | |||||
| </module> | |||||
+ 9
- 0
heredity/.idea/misc.xml
View File
| @ -0,0 +1,9 @@ | |||||
| <?xml version="1.0" encoding="UTF-8"?> | |||||
| <project version="4"> | |||||
| <component name="JavaScriptSettings"> | |||||
| <option name="languageLevel" value="ES6" /> | |||||
| </component> | |||||
| <component name="ProjectRootManager" version="2" languageLevel="JDK_11" default="false" project-jdk-name="Python 3.8" project-jdk-type="Python SDK"> | |||||
| <output url="file://$PROJECT_DIR$/out" /> | |||||
| </component> | |||||
| </project> | |||||
+ 8
- 0
heredity/.idea/modules.xml
View File
| @ -0,0 +1,8 @@ | |||||
| <?xml version="1.0" encoding="UTF-8"?> | |||||
| <project version="4"> | |||||
| <component name="ProjectModuleManager"> | |||||
| <modules> | |||||
| <module fileurl="file://$PROJECT_DIR$/.idea/heredity.iml" filepath="$PROJECT_DIR$/.idea/heredity.iml" /> | |||||
| </modules> | |||||
| </component> | |||||
| </project> | |||||
+ 4
- 0
heredity/data/family0.csv
View File
| @ -0,0 +1,4 @@ | |||||
| name,mother,father,trait | |||||
| Harry,Lily,James, | |||||
| James,,,1 | |||||
| Lily,,,0 | |||||
+ 7
- 0
heredity/data/family1.csv
View File
| @ -0,0 +1,7 @@ | |||||
| name,mother,father,trait | |||||
| Arthur,,,0 | |||||
| Charlie,Molly,Arthur,0 | |||||
| Fred,Molly,Arthur,1 | |||||
| Ginny,Molly,Arthur, | |||||
| Molly,,,0 | |||||
| Ron,Molly,Arthur, | |||||
+ 6
- 0
heredity/data/family2.csv
View File
| @ -0,0 +1,6 @@ | |||||
| name,mother,father,trait | |||||
| Arthur,,,0 | |||||
| Hermione,,,0 | |||||
| Molly,,, | |||||
| Ron,Molly,Arthur,0 | |||||
| Rose,Ron,Hermione,1 | |||||
+ 212
- 0
heredity/heredity.py
View File
| @ -0,0 +1,212 @@ | |||||
| import csv | |||||
| import itertools | |||||
| import sys | |||||
| PROBS = { | |||||
| # Unconditional probabilities for having gene | |||||
| "gene": { | |||||
| 2: 0.01, | |||||
| 1: 0.03, | |||||
| 0: 0.96 | |||||
| }, | |||||
| "trait": { | |||||
| # Probability of trait given two copies of gene | |||||
| 2: { | |||||
| True: 0.65, | |||||
| False: 0.35 | |||||
| }, | |||||
| # Probability of trait given one copy of gene | |||||
| 1: { | |||||
| True: 0.56, | |||||
| False: 0.44 | |||||
| }, | |||||
| # Probability of trait given no gene | |||||
| 0: { | |||||
| True: 0.01, | |||||
| False: 0.99 | |||||
| } | |||||
| }, | |||||
| # Mutation probability | |||||
| "mutation": 0.01 | |||||
| } | |||||
| def main(): | |||||
| # Check for proper usage | |||||
| if len(sys.argv) != 2: | |||||
| sys.exit("Usage: python heredity.py data.csv") | |||||
| people = load_data(sys.argv[1]) | |||||
| # Keep track of gene and trait probabilities for each person | |||||
| probabilities = { | |||||
| person: { | |||||
| "gene": { | |||||
| 2: 0, | |||||
| 1: 0, | |||||
| 0: 0 | |||||
| }, | |||||
| "trait": { | |||||
| True: 0, | |||||
| False: 0 | |||||
| } | |||||
| } | |||||
| for person in people | |||||
| } | |||||
| # Loop over all sets of people who might have the trait | |||||
| names = set(people) | |||||
| for have_trait in powerset(names): | |||||
| # Check if current set of people violates known information | |||||
| fails_evidence = any( | |||||
| (people[person]["trait"] is not None and | |||||
| people[person]["trait"] != (person in have_trait)) | |||||
| for person in names | |||||
| ) | |||||
| if fails_evidence: | |||||
| continue | |||||
| # Loop over all sets of people who might have the gene | |||||
| for one_gene in powerset(names): | |||||
| for two_genes in powerset(names - one_gene): | |||||
| # Update probabilities with new joint probability | |||||
| p = joint_probability(people, one_gene, two_genes, have_trait) | |||||
| update(probabilities, one_gene, two_genes, have_trait, p) | |||||
| # Ensure probabilities sum to 1 | |||||
| normalize(probabilities) | |||||
| # Print results | |||||
| for person in people: | |||||
| print(f"{person}:") | |||||
| for field in probabilities[person]: | |||||
| print(f" {field.capitalize()}:") | |||||
| for value in probabilities[person][field]: | |||||
| p = probabilities[person][field][value] | |||||
| print(f" {value}: {p:.4f}") | |||||
| def load_data(filename): | |||||
| """ | |||||
| Load gene and trait data from a file into a dictionary. | |||||
| File assumed to be a CSV containing fields name, mother, father, trait. | |||||
| mother, father must both be blank, or both be valid names in the CSV. | |||||
| trait should be 0 or 1 if trait is known, blank otherwise. | |||||
| """ | |||||
| data = dict() | |||||
| with open(filename) as f: | |||||
| reader = csv.DictReader(f) | |||||
| for row in reader: | |||||
| name = row["name"] | |||||
| data[name] = { | |||||
| "name": name, | |||||
| "mother": row["mother"] or None, | |||||
| "father": row["father"] or None, | |||||
| "trait": (True if row["trait"] == "1" else | |||||
| False if row["trait"] == "0" else None) | |||||
| } | |||||
| return data | |||||
| def powerset(s): | |||||
| """ | |||||
| Return a list of all possible subsets of set s. | |||||
| """ | |||||
| s = list(s) | |||||
| return [ | |||||
| set(s) for s in itertools.chain.from_iterable( | |||||
| itertools.combinations(s, r) for r in range(len(s) + 1) | |||||
| ) | |||||
| ] | |||||
| def get_info(person, one_gene, two_genes, have_trait): | |||||
| trait = person in have_trait | |||||
| gene = 0 | |||||
| if person in one_gene: | |||||
| gene = 1 | |||||
| elif person in two_genes: | |||||
| gene = 2 | |||||
| return gene, trait | |||||
| def joint_probability(people, one_gene, two_genes, have_trait): | |||||
| """ | |||||
| Compute and return a joint probability. | |||||
| The probability returned should be the probability that | |||||
| * everyone in set `one_gene` has one copy of the gene, and | |||||
| * everyone in set `two_genes` has two copies of the gene, and | |||||
| * everyone not in `one_gene` or `two_gene` does not have the gene, and | |||||
| * everyone in set `have_trait` has the trait, and | |||||
| * everyone not in set` have_trait` does not have the trait. | |||||
| """ | |||||
| def generate_prob(m_gene, f_gene, gene_combination): | |||||
| if m_gene == 1: | |||||
| m_prob = 0.5 | |||||
| else: | |||||
| m_prob = 0.99 if m_gene/2 == gene_combination[0] else 0.01 | |||||
| if f_gene == 1: | |||||
| f_prob = 0.5 | |||||
| else: | |||||
| f_prob = 0.99 if f_gene/2 == gene_combination[1] else 0.01 | |||||
| return m_prob * f_prob | |||||
| probabilities = [] | |||||
| for person in people: | |||||
| gene, trait = get_info(person, one_gene, two_genes, have_trait) | |||||
| if people[person]["mother"] and people[person]["father"]: | |||||
| mother_gene, foo = get_info(people[person]["mother"], one_gene, two_genes, have_trait) | |||||
| father_gene, foo = get_info(people[person]["father"], one_gene, two_genes, have_trait) | |||||
| if gene == 1: | |||||
| gene_prob = generate_prob(mother_gene, father_gene, (0, 1)) + generate_prob(mother_gene, father_gene, (1, 0)) | |||||
| else: | |||||
| gene_prob = generate_prob(mother_gene, father_gene, (gene/2, gene/2)) | |||||
| else: | |||||
| gene_prob = PROBS["gene"][gene] | |||||
| probabilities.append(gene_prob * PROBS["trait"][gene][trait]) | |||||
| joint_prob = 1 | |||||
| for p in probabilities: | |||||
| joint_prob *= p | |||||
| return joint_prob | |||||
| def update(probabilities, one_gene, two_genes, have_trait, p): | |||||
| for person in probabilities: | |||||
| gene, trait = get_info(person, one_gene, two_genes, have_trait) | |||||
| probabilities[person]["gene"][gene] += p | |||||
| probabilities[person]["trait"][trait] += p | |||||
| def normalize(probabilities): | |||||
| for person in probabilities: | |||||
| psum = 0 | |||||
| for gene in probabilities[person]["gene"]: | |||||
| psum += probabilities[person]["gene"][gene] | |||||
| gene_ratio = 1/psum | |||||
| for gene in probabilities[person]["gene"]: | |||||
| probabilities[person]["gene"][gene] *= gene_ratio | |||||
| psum = 0 | |||||
| for trait in probabilities[person]["trait"]: | |||||
| psum += probabilities[person]["trait"][trait] | |||||
| trait_ratio = 1/psum | |||||
| for trait in probabilities[person]["trait"]: | |||||
| probabilities[person]["trait"][trait] *= trait_ratio | |||||
| if __name__ == "__main__": | |||||
| main() | |||||
+ 0
- 0
heredity/stale_outputs_checked
View File
+ 8
- 0
knights/.idea/.gitignore
View File
| @ -0,0 +1,8 @@ | |||||
| # Default ignored files | |||||
| /shelf/ | |||||
| /workspace.xml | |||||
| # Datasource local storage ignored files | |||||
| /dataSources/ | |||||
| /dataSources.local.xml | |||||
| # Editor-based HTTP Client requests | |||||
| /httpRequests/ | |||||
+ 9
- 0
knights/.idea/knights.iml
View File
| @ -0,0 +1,9 @@ | |||||
| <?xml version="1.0" encoding="UTF-8"?> | |||||
| <module type="JAVA_MODULE" version="4"> | |||||
| <component name="NewModuleRootManager" inherit-compiler-output="true"> | |||||
| <exclude-output /> | |||||
| <content url="file://$MODULE_DIR$" /> | |||||
| <orderEntry type="inheritedJdk" /> | |||||
| <orderEntry type="sourceFolder" forTests="false" /> | |||||
| </component> | |||||
| </module> | |||||
+ 9
- 0
knights/.idea/misc.xml
View File
| @ -0,0 +1,9 @@ | |||||
| <?xml version="1.0" encoding="UTF-8"?> | |||||
| <project version="4"> | |||||
| <component name="JavaScriptSettings"> | |||||
| <option name="languageLevel" value="ES6" /> | |||||
| </component> | |||||
| <component name="ProjectRootManager" version="2" languageLevel="JDK_11" default="false" project-jdk-name="Python 3.8" project-jdk-type="Python SDK"> | |||||
| <output url="file://$PROJECT_DIR$/out" /> | |||||
| </component> | |||||
| </project> | |||||
+ 8
- 0
knights/.idea/modules.xml
View File
| @ -0,0 +1,8 @@ | |||||
| <?xml version="1.0" encoding="UTF-8"?> | |||||
| <project version="4"> | |||||
| <component name="ProjectModuleManager"> | |||||
| <modules> | |||||
| <module fileurl="file://$PROJECT_DIR$/.idea/knights.iml" filepath="$PROJECT_DIR$/.idea/knights.iml" /> | |||||
| </modules> | |||||
| </component> | |||||
| </project> | |||||
BIN
knights/__pycache__/logic.cpython-38.pyc
View File
+ 263
- 0
knights/logic.py
View File
| @ -0,0 +1,263 @@ | |||||
| import itertools | |||||
| class Sentence(): | |||||
| def evaluate(self, model): | |||||
| """Evaluates the logical sentence.""" | |||||
| raise Exception("nothing to evaluate") | |||||
| def formula(self): | |||||
| """Returns string formula representing logical sentence.""" | |||||
| return "" | |||||
| def symbols(self): | |||||
| """Returns a set of all symbols in the logical sentence.""" | |||||
| return set() | |||||
| @classmethod | |||||
| def validate(cls, sentence): | |||||
| if not isinstance(sentence, Sentence): | |||||
| raise TypeError("must be a logical sentence") | |||||
| @classmethod | |||||
| def parenthesize(cls, s): | |||||
| """Parenthesizes an expression if not already parenthesized.""" | |||||
| def balanced(s): | |||||
| """Checks if a string has balanced parentheses.""" | |||||
| count = 0 | |||||
| for c in s: | |||||
| if c == "(": | |||||
| count += 1 | |||||
| elif c == ")": | |||||
| if count <= 0: | |||||
| return False | |||||
| count -= 1 | |||||
| return count == 0 | |||||
| if not len(s) or s.isalpha() or ( | |||||
| s[0] == "(" and s[-1] == ")" and balanced(s[1:-1]) | |||||
| ): | |||||
| return s | |||||
| else: | |||||
| return f"({s})" | |||||
| class Symbol(Sentence): | |||||
| def __init__(self, name): | |||||
| self.name = name | |||||
| def __eq__(self, other): | |||||
| return isinstance(other, Symbol) and self.name == other.name | |||||
| def __hash__(self): | |||||
| return hash(("symbol", self.name)) | |||||
| def __repr__(self): | |||||
| return self.name | |||||
| def evaluate(self, model): | |||||
| try: | |||||
| return bool(model[self.name]) | |||||
| except KeyError: | |||||
| raise Exception(f"variable {self.name} not in model") | |||||
| def formula(self): | |||||
| return self.name | |||||
| def symbols(self): | |||||
| return {self.name} | |||||
| class Not(Sentence): | |||||
| def __init__(self, operand): | |||||
| Sentence.validate(operand) | |||||
| self.operand = operand | |||||
| def __eq__(self, other): | |||||
| return isinstance(other, Not) and self.operand == other.operand | |||||
| def __hash__(self): | |||||
| return hash(("not", hash(self.operand))) | |||||
| def __repr__(self): | |||||
| return f"Not({self.operand})" | |||||
| def evaluate(self, model): | |||||
| return not self.operand.evaluate(model) | |||||
| def formula(self): | |||||
| return "¬" + Sentence.parenthesize(self.operand.formula()) | |||||
| def symbols(self): | |||||
| return self.operand.symbols() | |||||
| class And(Sentence): | |||||
| def __init__(self, *conjuncts): | |||||
| for conjunct in conjuncts: | |||||
| Sentence.validate(conjunct) | |||||
| self.conjuncts = list(conjuncts) | |||||
| def __eq__(self, other): | |||||
| return isinstance(other, And) and self.conjuncts == other.conjuncts | |||||
| def __hash__(self): | |||||
| return hash( | |||||
| ("and", tuple(hash(conjunct) for conjunct in self.conjuncts)) | |||||
| ) | |||||
| def __repr__(self): | |||||
| conjunctions = ", ".join( | |||||
| [str(conjunct) for conjunct in self.conjuncts] | |||||
| ) | |||||
| return f"And({conjunctions})" | |||||
| def add(self, conjunct): | |||||
| Sentence.validate(conjunct) | |||||
| self.conjuncts.append(conjunct) | |||||
| def evaluate(self, model): | |||||
| return all(conjunct.evaluate(model) for conjunct in self.conjuncts) | |||||
| def formula(self): | |||||
| if len(self.conjuncts) == 1: | |||||
| return self.conjuncts[0].formula() | |||||
| return " ∧ ".join([Sentence.parenthesize(conjunct.formula()) | |||||
| for conjunct in self.conjuncts]) | |||||
| def symbols(self): | |||||
| return set.union(*[conjunct.symbols() for conjunct in self.conjuncts]) | |||||
| class Or(Sentence): | |||||
| def __init__(self, *disjuncts): | |||||
| for disjunct in disjuncts: | |||||
| Sentence.validate(disjunct) | |||||
| self.disjuncts = list(disjuncts) | |||||
| def __eq__(self, other): | |||||
| return isinstance(other, Or) and self.disjuncts == other.disjuncts | |||||
| def __hash__(self): | |||||
| return hash( | |||||
| ("or", tuple(hash(disjunct) for disjunct in self.disjuncts)) | |||||
| ) | |||||
| def __repr__(self): | |||||
| disjuncts = ", ".join([str(disjunct) for disjunct in self.disjuncts]) | |||||
| return f"Or({disjuncts})" | |||||
| def evaluate(self, model): | |||||
| return any(disjunct.evaluate(model) for disjunct in self.disjuncts) | |||||
| def formula(self): | |||||
| if len(self.disjuncts) == 1: | |||||
| return self.disjuncts[0].formula() | |||||
| return " ∨ ".join([Sentence.parenthesize(disjunct.formula()) | |||||
| for disjunct in self.disjuncts]) | |||||
| def symbols(self): | |||||
| return set.union(*[disjunct.symbols() for disjunct in self.disjuncts]) | |||||
| class Implication(Sentence): | |||||
| def __init__(self, antecedent, consequent): | |||||
| Sentence.validate(antecedent) | |||||
| Sentence.validate(consequent) | |||||
| self.antecedent = antecedent | |||||
| self.consequent = consequent | |||||
| def __eq__(self, other): | |||||
| return (isinstance(other, Implication) | |||||
| and self.antecedent == other.antecedent | |||||
| and self.consequent == other.consequent) | |||||
| def __hash__(self): | |||||
| return hash(("implies", hash(self.antecedent), hash(self.consequent))) | |||||
| def __repr__(self): | |||||
| return f"Implication({self.antecedent}, {self.consequent})" | |||||
| def evaluate(self, model): | |||||
| return ((not self.antecedent.evaluate(model)) | |||||
| or self.consequent.evaluate(model)) | |||||
| def formula(self): | |||||
| antecedent = Sentence.parenthesize(self.antecedent.formula()) | |||||
| consequent = Sentence.parenthesize(self.consequent.formula()) | |||||
| return f"{antecedent} => {consequent}" | |||||
| def symbols(self): | |||||
| return set.union(self.antecedent.symbols(), self.consequent.symbols()) | |||||
| class Biconditional(Sentence): | |||||
| def __init__(self, left, right): | |||||
| Sentence.validate(left) | |||||
| Sentence.validate(right) | |||||
| self.left = left | |||||
| self.right = right | |||||
| def __eq__(self, other): | |||||
| return (isinstance(other, Biconditional) | |||||
| and self.left == other.left | |||||
| and self.right == other.right) | |||||
| def __hash__(self): | |||||
| return hash(("biconditional", hash(self.left), hash(self.right))) | |||||
| def __repr__(self): | |||||
| return f"Biconditional({self.left}, {self.right})" | |||||
| def evaluate(self, model): | |||||
| return ((self.left.evaluate(model) | |||||
| and self.right.evaluate(model)) | |||||
| or (not self.left.evaluate(model) | |||||
| and not self.right.evaluate(model))) | |||||
| def formula(self): | |||||
| left = Sentence.parenthesize(str(self.left)) | |||||
| right = Sentence.parenthesize(str(self.right)) | |||||
| return f"{left} <=> {right}" | |||||
| def symbols(self): | |||||
| return set.union(self.left.symbols(), self.right.symbols()) | |||||
| def model_check(knowledge, query): | |||||
| """Checks if knowledge base entails query.""" | |||||
| def check_all(knowledge, query, symbols, model): | |||||
| """Checks if knowledge base entails query, given a particular model.""" | |||||
| # If model has an assignment for each symbol | |||||
| if not symbols: | |||||
| # If knowledge base is true in model, then query must also be true | |||||
| if knowledge.evaluate(model): | |||||
| return query.evaluate(model) | |||||
| return True | |||||
| else: | |||||
| # Choose one of the remaining unused symbols | |||||
| remaining = symbols.copy() | |||||
| p = remaining.pop() | |||||
| # Create a model where the symbol is true | |||||
| model_true = model.copy() | |||||
| model_true[p] = True | |||||
| # Create a model where the symbol is false | |||||
| model_false = model.copy() | |||||
| model_false[p] = False | |||||
| # Ensure entailment holds in both models | |||||
| return (check_all(knowledge, query, remaining, model_true) and | |||||
| check_all(knowledge, query, remaining, model_false)) | |||||
| # Get all symbols in both knowledge and query | |||||
| symbols = set.union(knowledge.symbols(), query.symbols()) | |||||
| # Check that knowledge entails query | |||||
| return check_all(knowledge, query, symbols, dict()) | |||||
+ 76
- 0
knights/puzzle.py
View File
| @ -0,0 +1,76 @@ | |||||
| from logic import * | |||||
| AKnight = Symbol("A is a Knight") | |||||
| AKnave = Symbol("A is a Knave") | |||||
| BKnight = Symbol("B is a Knight") | |||||
| BKnave = Symbol("B is a Knave") | |||||
| CKnight = Symbol("C is a Knight") | |||||
| CKnave = Symbol("C is a Knave") | |||||
| # Puzzle 0 | |||||
| # A says "I am both a knight and a knave." | |||||
| knowledge0 = And( | |||||
| Not(And(AKnave, AKnight)), | |||||
| Or(AKnave, AKnight), | |||||
| Implication(AKnight, And(AKnave, AKnight)) | |||||
| ) | |||||
| # Puzzle 1 | |||||
| # A says "We are both knaves." | |||||
| # B says nothing. | |||||
| knowledge1 = And( | |||||
| Not(And(AKnave, AKnight)), Or(AKnave, AKnight), | |||||
| Not(And(BKnave, BKnight)), Or(BKnave, BKnight), | |||||
| Implication(AKnight, And(AKnave, BKnave)), | |||||
| Implication(AKnave, Not(And(AKnave, BKnave))) | |||||
| ) | |||||
| # Puzzle 2 | |||||
| # A says "We are the same kind." | |||||
| # B says "We are of different kinds." | |||||
| knowledge2 = And( | |||||
| Not(And(AKnave, AKnight)), Or(AKnave, AKnight), | |||||
| Not(And(BKnave, BKnight)), Or(BKnave, BKnight), | |||||
| Implication(AKnight, And(AKnight, BKnight)), | |||||
| Implication(BKnave, And(AKnight, BKnight)), | |||||
| Implication(BKnight, And(Not(And(BKnight, AKnight)), Not(And(BKnave, AKnave)))) | |||||
| ) | |||||
| # Puzzle 3 | |||||
| # A says either "I am a knight." or "I am a knave.", but you don't know which. | |||||
| # B says "A said 'I am a knave'." | |||||
| # B says "C is a knave." | |||||
| # C says "A is a knight." | |||||
| knowledge3 = And( | |||||
| Not(And(AKnave, AKnight)), Or(AKnave, AKnight), | |||||
| Not(And(BKnave, BKnight)), Or(BKnave, BKnight), | |||||
| Not(And(CKnave, CKnight)), Or(CKnave, CKnight), | |||||
| Implication(AKnave, AKnight), | |||||
| Biconditional(AKnave, BKnight), | |||||
| Biconditional(BKnave, CKnight), | |||||
| Biconditional(AKnight, CKnight) | |||||
| ) | |||||
| def main(): | |||||
| symbols = [AKnight, AKnave, BKnight, BKnave, CKnight, CKnave] | |||||
| puzzles = [ | |||||
| ("Puzzle 0", knowledge0), | |||||
| ("Puzzle 1", knowledge1), | |||||
| ("Puzzle 2", knowledge2), | |||||
| ("Puzzle 3", knowledge3) | |||||
| ] | |||||
| for puzzle, knowledge in puzzles: | |||||
| print(puzzle) | |||||
| if len(knowledge.conjuncts) == 0: | |||||
| print(" Not yet implemented.") | |||||
| else: | |||||
| for symbol in symbols: | |||||
| if model_check(knowledge, symbol): | |||||
| print(f" {symbol}") | |||||
| if __name__ == "__main__": | |||||
| main() | |||||
+ 8
- 0
minesweeper/.idea/.gitignore
View File
| @ -0,0 +1,8 @@ | |||||
| # Default ignored files | |||||
| /shelf/ | |||||
| /workspace.xml | |||||
| # Datasource local storage ignored files | |||||
| /dataSources/ | |||||
| /dataSources.local.xml | |||||
| # Editor-based HTTP Client requests | |||||
| /httpRequests/ | |||||
+ 15
- 0
minesweeper/.idea/minesweeper.iml
View File
| @ -0,0 +1,15 @@ | |||||
| <?xml version="1.0" encoding="UTF-8"?> | |||||
| <module type="JAVA_MODULE" version="4"> | |||||
| <component name="FacetManager"> | |||||
| <facet type="Python" name="Python"> | |||||
| <configuration sdkName="Python 3.8" /> | |||||
| </facet> | |||||
| </component> | |||||
| <component name="NewModuleRootManager" inherit-compiler-output="true"> | |||||
| <exclude-output /> | |||||
| <content url="file://$MODULE_DIR$" /> | |||||
| <orderEntry type="inheritedJdk" /> | |||||
| <orderEntry type="sourceFolder" forTests="false" /> | |||||
| <orderEntry type="library" name="Python 3.8 interpreter library" level="application" /> | |||||
| </component> | |||||
| </module> | |||||
+ 9
- 0
minesweeper/.idea/misc.xml
View File
| @ -0,0 +1,9 @@ | |||||
| <?xml version="1.0" encoding="UTF-8"?> | |||||
| <project version="4"> | |||||
| <component name="JavaScriptSettings"> | |||||
| <option name="languageLevel" value="ES6" /> | |||||
| </component> | |||||
| <component name="ProjectRootManager" version="2" languageLevel="JDK_11" default="false" project-jdk-name="Python 3.8" project-jdk-type="Python SDK"> | |||||
| <output url="file://$PROJECT_DIR$/out" /> | |||||
| </component> | |||||
| </project> | |||||
+ 8
- 0
minesweeper/.idea/modules.xml
View File
| @ -0,0 +1,8 @@ | |||||
| <?xml version="1.0" encoding="UTF-8"?> | |||||
| <project version="4"> | |||||
| <component name="ProjectModuleManager"> | |||||
| <modules> | |||||
| <module fileurl="file://$PROJECT_DIR$/.idea/minesweeper.iml" filepath="$PROJECT_DIR$/.idea/minesweeper.iml" /> | |||||
| </modules> | |||||
| </component> | |||||
| </project> | |||||
BIN
minesweeper/__pycache__/minesweeper.cpython-38.pyc
View File
BIN
minesweeper/assets/fonts/OpenSans-Regular.ttf
View File
BIN
minesweeper/assets/images/flag.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 650 | Height: 793 | Size: 18 KiB |
BIN
minesweeper/assets/images/mine.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 635 | Height: 635 | Size: 16 KiB |
+ 253
- 0
minesweeper/minesweeper.py
View File
| @ -0,0 +1,253 @@ | |||||
| import itertools | |||||
| import random | |||||
| class Minesweeper(): | |||||
| """ | |||||
| Minesweeper game representation | |||||
| """ | |||||
| def __init__(self, height=8, width=8, mines=8): | |||||
| # Set initial width, height, and number of mines | |||||
| self.height = height | |||||
| self.width = width | |||||
| self.mines = set() | |||||
| # Initialize an empty field with no mines | |||||
| self.board = [] | |||||
| for i in range(self.height): | |||||
| row = [] | |||||
| for j in range(self.width): | |||||
| row.append(False) | |||||
| self.board.append(row) | |||||
| # Add mines randomly | |||||
| while len(self.mines) != mines: | |||||
| i = random.randrange(height) | |||||
| j = random.randrange(width) | |||||
| if not self.board[i][j]: | |||||
| self.mines.add((i, j)) | |||||
| self.board[i][j] = True | |||||
| # At first, player has found no mines | |||||
| self.mines_found = set() | |||||
| def print(self): | |||||
| """ | |||||
| Prints a text-based representation | |||||
| of where mines are located. | |||||
| """ | |||||
| for i in range(self.height): | |||||
| print("--" * self.width + "-") | |||||
| for j in range(self.width): | |||||
| if self.board[i][j]: | |||||
| print("|X", end="") | |||||
| else: | |||||
| print("| ", end="") | |||||
| print("|") | |||||
| print("--" * self.width + "-") | |||||
| def is_mine(self, cell): | |||||
| i, j = cell | |||||
| return self.board[i][j] | |||||
| def nearby_mines(self, cell): | |||||
| """ | |||||
| Returns the number of mines that are | |||||
| within one row and column of a given cell, | |||||
| not including the cell itself. | |||||
| """ | |||||
| # Keep count of nearby mines | |||||
| count = 0 | |||||
| # Loop over all cells within one row and column | |||||
| for i in range(cell[0] - 1, cell[0] + 2): | |||||
| for j in range(cell[1] - 1, cell[1] + 2): | |||||
| # Ignore the cell itself | |||||
| if (i, j) == cell: | |||||
| continue | |||||
| # Update count if cell in bounds and is mine | |||||
| if 0 <= i < self.height and 0 <= j < self.width: | |||||
| if self.board[i][j]: | |||||
| count += 1 | |||||
| return count | |||||
| def won(self): | |||||
| """ | |||||
| Checks if all mines have been flagged. | |||||
| """ | |||||
| return self.mines_found == self.mines | |||||
| class Sentence(): | |||||
| """ | |||||
| Logical statement about a Minesweeper game | |||||
| A sentence consists of a set of board cells, | |||||
| and a count of the number of those cells which are mines. | |||||
| """ | |||||
| def __init__(self, cells, count): | |||||
| self.cells = set(cells) | |||||
| self.count = count | |||||
| def __eq__(self, other): | |||||
| return self.cells == other.cells and self.count == other.count | |||||
| def __str__(self): | |||||
| return f"{self.cells} = {self.count}" | |||||
| def known_mines(self): | |||||
| if self.cells.__len__() == self.count: | |||||
| return self.cells | |||||
| return set() | |||||
| def known_safes(self): | |||||
| if self.count == 0: | |||||
| return self.cells | |||||
| return set() | |||||
| def mark_mine(self, cell): # Remove cell from set and decrease count by one | |||||
| if cell in self.cells: | |||||
| self.cells.remove(cell) | |||||
| self.count -= 1 | |||||
| def mark_safe(self, cell): # Remove safe cell from cells set | |||||
| if cell in self.cells: | |||||
| self.cells.remove(cell) | |||||
| class MinesweeperAI(): | |||||
| """ | |||||
| Minesweeper game player | |||||
| """ | |||||
| def __init__(self, height=8, width=8): | |||||
| # Set initial height and width | |||||
| self.height = height | |||||
| self.width = width | |||||
| # Keep track of which cells have been clicked on | |||||
| self.moves_made = set() | |||||
| # Keep track of cells known to be safe or mines | |||||
| self.mines = set() | |||||
| self.safes = set() | |||||
| # List of sentences about the game known to be true | |||||
| self.knowledge = [] | |||||
| def mark_mine(self, cell): | |||||
| """ | |||||
| Marks a cell as a mine, and updates all knowledge | |||||
| to mark that cell as a mine as well. | |||||
| """ | |||||
| self.mines.add(cell) | |||||
| for sentence in self.knowledge: | |||||
| sentence.mark_mine(cell) | |||||
| def mark_safe(self, cell): | |||||
| """ | |||||
| Marks a cell as safe, and updates all knowledge | |||||
| to mark that cell as safe as well. | |||||
| """ | |||||
| self.safes.add(cell) | |||||
| for sentence in self.knowledge: | |||||
| sentence.mark_safe(cell) | |||||
| def add_knowledge(self, cell, count): | |||||
| """ | |||||
| Called when the Minesweeper board tells us, for a given | |||||
| safe cell, how many neighboring cells have mines in them. | |||||
| This function should: | |||||
| 1) mark the cell as a move that has been made | |||||
| 2) mark the cell as safe | |||||
| 3) add a new sentence to the AI's knowledge base | |||||
| based on the value of `cell` and `count` | |||||
| 4) mark any additional cells as safe or as mines | |||||
| if it can be concluded based on the AI's knowledge base | |||||
| 5) add any new sentences to the AI's knowledge base | |||||
| if they can be inferred from existing knowledge | |||||
| """ | |||||
| self.moves_made.add(cell) #Store information about the cell | |||||
| self.mark_safe(cell) | |||||
| surrounding_cells = set() | |||||
| for i in range(cell[0]-1 if cell[0] - 1 >= 0 else 0, cell[0]+2 if cell[0] + 2 <= self.width else self.width): | |||||
| for j in range(cell[1]-1 if cell[1] - 1 >= 0 else 0, cell[1]+2 if cell[1] + 2 <= self.height else self.height): | |||||
| count -= int((i, j) in self.mines) | |||||
| if (i, j) not in self.safes.union(self.mines): | |||||
| surrounding_cells.add((i, j)) | |||||
| new_knowledge = Sentence(surrounding_cells, count) | |||||
| if new_knowledge in self.knowledge: | |||||
| return | |||||
| inferred_knowledge = [] | |||||
| knowledge_cpy = self.knowledge.copy() | |||||
| popped = 0 | |||||
| for i, sentence in enumerate(knowledge_cpy): | |||||
| if sentence.cells == set(): | |||||
| self.knowledge.pop(i - popped) | |||||
| popped += 1 | |||||
| continue | |||||
| if new_knowledge.cells.issubset(sentence.cells): | |||||
| new_cells = sentence.cells - new_knowledge.cells | |||||
| new_count = sentence.count - new_knowledge.count | |||||
| new_sentence = Sentence(new_cells, new_count) | |||||
| inferred_knowledge.append(Sentence(new_cells, new_count)) | |||||
| elif sentence.cells.issubset(new_knowledge.cells): | |||||
| new_cells = new_knowledge.cells - sentence.cells | |||||
| new_count = new_knowledge.count - sentence.count | |||||
| new_sentence = Sentence(new_cells, new_count) | |||||
| inferred_knowledge.append(new_sentence) | |||||
| for i in inferred_knowledge: | |||||
| if i.known_safes() != set(): | |||||
| for j in i.cells: | |||||
| self.mark_safe(j) | |||||
| elif i.known_mines() != set(): | |||||
| for j in i.cells: | |||||
| self.mark_mine(j) | |||||
| for i in self.knowledge: | |||||
| cells = i.cells.copy() | |||||
| if i.known_safes() != set(): | |||||
| for j in cells: | |||||
| self.mark_safe(j) | |||||
| elif i.known_mines() != set(): | |||||
| for j in cells: | |||||
| self.mark_mine(j) | |||||
| inferred_knowledge.append(new_knowledge) | |||||
| for i in inferred_knowledge: | |||||
| exists = False | |||||
| for j in self.knowledge: | |||||
| if i == j: | |||||
| exists = True | |||||
| if not exists: | |||||
| self.knowledge.append(i) | |||||
| def make_safe_move(self): | |||||
| available_moves = self.safes - self.moves_made | |||||
| for s in self.knowledge: | |||||
| available_moves = available_moves.union(s.known_safes()) | |||||
| if available_moves.__len__() == 0: | |||||
| return None | |||||
| return available_moves.pop() | |||||
| def make_random_move(self): | |||||
| unavailable_moves = self.moves_made.union(self.mines) | |||||
| available_moves = set() | |||||
| for i in range(self.width): | |||||
| for j in range(self.height): | |||||
| if (i, j) not in unavailable_moves: | |||||
| available_moves.add((i, j)) | |||||
| if available_moves.__len__() == 0: | |||||
| return None | |||||
| return available_moves.pop() | |||||
+ 1
- 0
minesweeper/requirements.txt
View File
| @ -0,0 +1 @@ | |||||
| pygame | |||||
+ 222
- 0
minesweeper/runner.py
View File
| @ -0,0 +1,222 @@ | |||||
| import pygame | |||||
| import sys | |||||
| import time | |||||
| from minesweeper import Minesweeper, MinesweeperAI | |||||
| HEIGHT = 8 | |||||
| WIDTH = 8 | |||||
| MINES = 8 | |||||
| # Colors | |||||
| BLACK = (0, 0, 0) | |||||
| GRAY = (180, 180, 180) | |||||
| WHITE = (255, 255, 255) | |||||
| # Create game | |||||
| pygame.init() | |||||
| size = width, height = 600, 400 | |||||
| screen = pygame.display.set_mode(size) | |||||
| # Fonts | |||||
| OPEN_SANS = "assets/fonts/OpenSans-Regular.ttf" | |||||
| smallFont = pygame.font.Font(OPEN_SANS, 20) | |||||
| mediumFont = pygame.font.Font(OPEN_SANS, 28) | |||||
| largeFont = pygame.font.Font(OPEN_SANS, 40) | |||||
| # Compute board size | |||||
| BOARD_PADDING = 20 | |||||
| board_width = ((2 / 3) * width) - (BOARD_PADDING * 2) | |||||
| board_height = height - (BOARD_PADDING * 2) | |||||
| cell_size = int(min(board_width / WIDTH, board_height / HEIGHT)) | |||||
| board_origin = (BOARD_PADDING, BOARD_PADDING) | |||||
| # Add images | |||||
| flag = pygame.image.load("assets/images/flag.png") | |||||
| flag = pygame.transform.scale(flag, (cell_size, cell_size)) | |||||
| mine = pygame.image.load("assets/images/mine.png") | |||||
| mine = pygame.transform.scale(mine, (cell_size, cell_size)) | |||||
| # Create game and AI agent | |||||
| game = Minesweeper(height=HEIGHT, width=WIDTH, mines=MINES) | |||||
| ai = MinesweeperAI(height=HEIGHT, width=WIDTH) | |||||
| # Keep track of revealed cells, flagged cells, and if a mine was hit | |||||
| revealed = set() | |||||
| flags = set() | |||||
| lost = False | |||||
| # Show instructions initially | |||||
| instructions = True | |||||
| while True: | |||||
| # Check if game quit | |||||
| for event in pygame.event.get(): | |||||
| if event.type == pygame.QUIT: | |||||
| sys.exit() | |||||
| screen.fill(BLACK) | |||||
| # Show game instructions | |||||
| if instructions: | |||||
| # Title | |||||
| title = largeFont.render("Play Minesweeper", True, WHITE) | |||||
| titleRect = title.get_rect() | |||||
| titleRect.center = ((width / 2), 50) | |||||
| screen.blit(title, titleRect) | |||||
| # Rules | |||||
| rules = [ | |||||
| "Click a cell to reveal it.", | |||||
| "Right-click a cell to mark it as a mine.", | |||||
| "Mark all mines successfully to win!" | |||||
| ] | |||||
| for i, rule in enumerate(rules): | |||||
| line = smallFont.render(rule, True, WHITE) | |||||
| lineRect = line.get_rect() | |||||
| lineRect.center = ((width / 2), 150 + 30 * i) | |||||
| screen.blit(line, lineRect) | |||||
| # Play game button | |||||
| buttonRect = pygame.Rect((width / 4), (3 / 4) * height, width / 2, 50) | |||||
| buttonText = mediumFont.render("Play Game", True, BLACK) | |||||
| buttonTextRect = buttonText.get_rect() | |||||
| buttonTextRect.center = buttonRect.center | |||||
| pygame.draw.rect(screen, WHITE, buttonRect) | |||||
| screen.blit(buttonText, buttonTextRect) | |||||
| # Check if play button clicked | |||||
| click, _, _ = pygame.mouse.get_pressed() | |||||
| if click == 1: | |||||
| mouse = pygame.mouse.get_pos() | |||||
| if buttonRect.collidepoint(mouse): | |||||
| instructions = False | |||||
| time.sleep(0.3) | |||||
| pygame.display.flip() | |||||
| continue | |||||
| # Draw board | |||||
| cells = [] | |||||
| for i in range(HEIGHT): | |||||
| row = [] | |||||
| for j in range(WIDTH): | |||||
| # Draw rectangle for cell | |||||
| rect = pygame.Rect( | |||||
| board_origin[0] + j * cell_size, | |||||
| board_origin[1] + i * cell_size, | |||||
| cell_size, cell_size | |||||
| ) | |||||
| pygame.draw.rect(screen, GRAY, rect) | |||||
| pygame.draw.rect(screen, WHITE, rect, 3) | |||||
| # Add a mine, flag, or number if needed | |||||
| if game.is_mine((i, j)) and lost: | |||||
| screen.blit(mine, rect) | |||||
| elif (i, j) in flags: | |||||
| screen.blit(flag, rect) | |||||
| elif (i, j) in revealed: | |||||
| neighbors = smallFont.render( | |||||
| str(game.nearby_mines((i, j))), | |||||
| True, BLACK | |||||
| ) | |||||
| neighborsTextRect = neighbors.get_rect() | |||||
| neighborsTextRect.center = rect.center | |||||
| screen.blit(neighbors, neighborsTextRect) | |||||
| row.append(rect) | |||||
| cells.append(row) | |||||
| # AI Move button | |||||
| aiButton = pygame.Rect( | |||||
| (2 / 3) * width + BOARD_PADDING, (1 / 3) * height - 50, | |||||
| (width / 3) - BOARD_PADDING * 2, 50 | |||||
| ) | |||||
| buttonText = mediumFont.render("AI Move", True, BLACK) | |||||
| buttonRect = buttonText.get_rect() | |||||
| buttonRect.center = aiButton.center | |||||
| pygame.draw.rect(screen, WHITE, aiButton) | |||||
| screen.blit(buttonText, buttonRect) | |||||
| # Reset button | |||||
| resetButton = pygame.Rect( | |||||
| (2 / 3) * width + BOARD_PADDING, (1 / 3) * height + 20, | |||||
| (width / 3) - BOARD_PADDING * 2, 50 | |||||
| ) | |||||
| buttonText = mediumFont.render("Reset", True, BLACK) | |||||
| buttonRect = buttonText.get_rect() | |||||
| buttonRect.center = resetButton.center | |||||
| pygame.draw.rect(screen, WHITE, resetButton) | |||||
| screen.blit(buttonText, buttonRect) | |||||
| # Display text | |||||
| text = "Lost" if lost else "Won" if game.mines == flags else "" | |||||
| text = mediumFont.render(text, True, WHITE) | |||||
| textRect = text.get_rect() | |||||
| textRect.center = ((5 / 6) * width, (2 / 3) * height) | |||||
| screen.blit(text, textRect) | |||||
| move = None | |||||
| left, _, right = pygame.mouse.get_pressed() | |||||
| # Check for a right-click to toggle flagging | |||||
| if right == 1 and not lost: | |||||
| mouse = pygame.mouse.get_pos() | |||||
| for i in range(HEIGHT): | |||||
| for j in range(WIDTH): | |||||
| if cells[i][j].collidepoint(mouse) and (i, j) not in revealed: | |||||
| if (i, j) in flags: | |||||
| flags.remove((i, j)) | |||||
| else: | |||||
| flags.add((i, j)) | |||||
| time.sleep(0.2) | |||||
| elif left == 1: | |||||
| mouse = pygame.mouse.get_pos() | |||||
| # If AI button clicked, make an AI move | |||||
| if aiButton.collidepoint(mouse) and not lost: | |||||
| move = ai.make_safe_move() | |||||
| if move is None: | |||||
| move = ai.make_random_move() | |||||
| if move is None: | |||||
| flags = ai.mines.copy() | |||||
| print("No moves left to make.") | |||||
| else: | |||||
| print("No known safe moves, AI making random move.") | |||||
| else: | |||||
| print("AI making safe move.") | |||||
| time.sleep(0.2) | |||||
| # Reset game state | |||||
| elif resetButton.collidepoint(mouse): | |||||
| game = Minesweeper(height=HEIGHT, width=WIDTH, mines=MINES) | |||||
| ai = MinesweeperAI(height=HEIGHT, width=WIDTH) | |||||
| revealed = set() | |||||
| flags = set() | |||||
| lost = False | |||||
| continue | |||||
| # User-made move | |||||
| elif not lost: | |||||
| for i in range(HEIGHT): | |||||
| for j in range(WIDTH): | |||||
| if (cells[i][j].collidepoint(mouse) | |||||
| and (i, j) not in flags | |||||
| and (i, j) not in revealed): | |||||
| move = (i, j) | |||||
| # Make move and update AI knowledge | |||||
| if move: | |||||
| if game.is_mine(move): | |||||
| lost = True | |||||
| else: | |||||
| nearby = game.nearby_mines(move) | |||||
| revealed.add(move) | |||||
| ai.add_knowledge(move, nearby) | |||||
| pygame.display.flip() | |||||
+ 8
- 0
nim/.idea/.gitignore
View File
| @ -0,0 +1,8 @@ | |||||
| # Default ignored files | |||||
| /shelf/ | |||||
| /workspace.xml | |||||
| # Datasource local storage ignored files | |||||
| /dataSources/ | |||||
| /dataSources.local.xml | |||||
| # Editor-based HTTP Client requests | |||||
| /httpRequests/ | |||||
+ 9
- 0
nim/.idea/misc.xml
View File
| @ -0,0 +1,9 @@ | |||||
| <?xml version="1.0" encoding="UTF-8"?> | |||||
| <project version="4"> | |||||
| <component name="JavaScriptSettings"> | |||||
| <option name="languageLevel" value="ES6" /> | |||||
| </component> | |||||
| <component name="ProjectRootManager" version="2" languageLevel="JDK_11" default="false" project-jdk-name="Python 3.8" project-jdk-type="Python SDK"> | |||||
| <output url="file://$PROJECT_DIR$/out" /> | |||||
| </component> | |||||
| </project> | |||||
+ 8
- 0
nim/.idea/modules.xml
View File
| @ -0,0 +1,8 @@ | |||||
| <?xml version="1.0" encoding="UTF-8"?> | |||||
| <project version="4"> | |||||
| <component name="ProjectModuleManager"> | |||||
| <modules> | |||||
| <module fileurl="file://$PROJECT_DIR$/.idea/nim.iml" filepath="$PROJECT_DIR$/.idea/nim.iml" /> | |||||
| </modules> | |||||
| </component> | |||||
| </project> | |||||
+ 9
- 0
nim/.idea/nim.iml
View File
| @ -0,0 +1,9 @@ | |||||
| <?xml version="1.0" encoding="UTF-8"?> | |||||
| <module type="JAVA_MODULE" version="4"> | |||||
| <component name="NewModuleRootManager" inherit-compiler-output="true"> | |||||
| <exclude-output /> | |||||
| <content url="file://$MODULE_DIR$" /> | |||||
| <orderEntry type="inheritedJdk" /> | |||||
| <orderEntry type="sourceFolder" forTests="false" /> | |||||
| </component> | |||||
| </module> | |||||
BIN
nim/__pycache__/nim.cpython-38.pyc
View File
+ 302
- 0
nim/nim.py
View File
| @ -0,0 +1,302 @@ | |||||
| import math | |||||
| import random | |||||
| import time | |||||
| class Nim(): | |||||
| def __init__(self, initial=[1, 3, 5, 7]): | |||||
| """ | |||||
| Initialize game board. | |||||
| Each game board has | |||||
| - `piles`: a list of how many elements remain in each pile | |||||
| - `player`: 0 or 1 to indicate which player's turn | |||||
| - `winner`: None, 0, or 1 to indicate who the winner is | |||||
| """ | |||||
| self.piles = initial.copy() | |||||
| self.player = 0 | |||||
| self.winner = None | |||||
| @classmethod | |||||
| def available_actions(cls, piles): | |||||
| """ | |||||
| Nim.available_actions(piles) takes a `piles` list as input | |||||
| and returns all of the available actions `(i, j)` in that state. | |||||
| Action `(i, j)` represents the action of removing `j` items | |||||
| from pile `i` (where piles are 0-indexed). | |||||
| """ | |||||
| actions = set() | |||||
| for i, pile in enumerate(piles): | |||||
| for j in range(1, pile + 1): | |||||
| actions.add((i, j)) | |||||
| return actions | |||||
| @classmethod | |||||
| def other_player(cls, player): | |||||
| """ | |||||
| Nim.other_player(player) returns the player that is not | |||||
| `player`. Assumes `player` is either 0 or 1. | |||||
| """ | |||||
| return 0 if player == 1 else 1 | |||||
| def switch_player(self): | |||||
| """ | |||||
| Switch the current player to the other player. | |||||
| """ | |||||
| self.player = Nim.other_player(self.player) | |||||
| def move(self, action): | |||||
| """ | |||||
| Make the move `action` for the current player. | |||||
| `action` must be a tuple `(i, j)`. | |||||
| """ | |||||
| pile, count = action | |||||
| # Check for errors | |||||
| if self.winner is not None: | |||||
| raise Exception("Game already won") | |||||
| elif pile < 0 or pile >= len(self.piles): | |||||
| raise Exception("Invalid pile") | |||||
| elif count < 1 or count > self.piles[pile]: | |||||
| raise Exception("Invalid number of objects") | |||||
| # Update pile | |||||
| self.piles[pile] -= count | |||||
| self.switch_player() | |||||
| # Check for a winner | |||||
| if all(pile == 0 for pile in self.piles): | |||||
| self.winner = self.player | |||||
| class NimAI(): | |||||
| def __init__(self, alpha=0.5, epsilon=0.2): | |||||
| """ | |||||
| Initialize AI with an empty Q-learning dictionary, | |||||
| an alpha (learning) rate, and an epsilon rate. | |||||
| The Q-learning dictionary maps `(state, action)` | |||||
| pairs to a Q-value (a number). | |||||
| - `state` is a tuple of remaining piles, e.g. (1, 1, 4, 4) | |||||
| - `action` is a tuple `(i, j)` for an action | |||||
| """ | |||||
| self.q = dict() | |||||
| self.alpha = alpha | |||||
| self.epsilon = epsilon | |||||
| def update(self, old_state, action, new_state, reward): | |||||
| """ | |||||
| Update Q-learning model, given an old state, an action taken | |||||
| in that state, a new resulting state, and the reward received | |||||
| from taking that action. | |||||
| """ | |||||
| old = self.get_q_value(old_state, action) | |||||
| best_future = self.best_future_reward(new_state) | |||||
| self.update_q_value(old_state, action, old, reward, best_future) | |||||
| def get_q_value(self, state, action): | |||||
| """ | |||||
| Return the Q-value for the state `state` and the action `action`. | |||||
| If no Q-value exists yet in `self.q`, return 0. | |||||
| """ | |||||
| if (tuple(state), action,) not in self.q: | |||||
| return 0 | |||||
| return self.q[(tuple(state), action)] | |||||
| def update_q_value(self, state, action, old_q, reward, future_rewards): | |||||
| """ | |||||
| Update the Q-value for the state `state` and the action `action` | |||||
| given the previous Q-value `old_q`, a current reward `reward`, | |||||
| and an estiamte of future rewards `future_rewards`. | |||||
| Use the formula: | |||||
| Q(s, a) <- old value estimate | |||||
| + alpha * (new value estimate - old value estimate) | |||||
| where `old value estimate` is the previous Q-value, | |||||
| `alpha` is the learning rate, and `new value estimate` | |||||
| is the sum of the current reward and estimated future rewards. | |||||
| """ | |||||
| self.q[(tuple(state), action)] = old_q + self.alpha*(reward + future_rewards - old_q) | |||||
| def best_future_reward(self, state): | |||||
| """ | |||||
| Given a state `state`, consider all possible `(state, action)` | |||||
| pairs available in that state and return the maximum of all | |||||
| of their Q-values. | |||||
| Use 0 as the Q-value if a `(state, action)` pair has no | |||||
| Q-value in `self.q`. If there are no available actions in | |||||
| `state`, return 0. | |||||
| """ | |||||
| actions = Nim.available_actions(state) | |||||
| if not actions: | |||||
| return 0 | |||||
| best = [0, set()] | |||||
| for i in actions: | |||||
| val = self.get_q_value(state, i) | |||||
| if not val: | |||||
| continue | |||||
| elif val > best[0]: | |||||
| best[1] = {val} | |||||
| elif val == best[0]: | |||||
| best[1].add(val) | |||||
| if best[1]: | |||||
| return next(iter(best[1])) | |||||
| else: | |||||
| return 0 | |||||
| def choose_action(self, state, epsilon=True): | |||||
| """ | |||||
| Given a state `state`, return an action `(i, j)` to take. | |||||
| If `epsilon` is `False`, then return the best action | |||||
| available in the state (the one with the highest Q-value, | |||||
| using 0 for pairs that have no Q-values). | |||||
| If `epsilon` is `True`, then with probability | |||||
| `self.epsilon` choose a random available action, | |||||
| otherwise choose the best action available. | |||||
| If multiple actions have the same Q-value, any of those | |||||
| options is an acceptable return value. | |||||
| """ | |||||
| actions = Nim.available_actions(state) | |||||
| if epsilon: | |||||
| epsilon = self.epsilon * 100 | |||||
| else: | |||||
| epsilon = 0 | |||||
| if 100 - random.randint(0, 100) >= epsilon: | |||||
| best = [0, set()] | |||||
| for i in actions: | |||||
| val = self.get_q_value(state, i) | |||||
| if not val: | |||||
| continue | |||||
| elif val > best[0]: | |||||
| best[1] = {i} | |||||
| elif val == best[0]: | |||||
| best[1].add(i) | |||||
| if best[1]: | |||||
| return next(iter(best[1])) | |||||
| else: | |||||
| return random.sample(actions, 1)[0] | |||||
| else: | |||||
| return random.sample(actions, 1)[0] | |||||
| def train(n): | |||||
| """ | |||||
| Train an AI by playing `n` games against itself. | |||||
| """ | |||||
| player = NimAI() | |||||
| # Play n games | |||||
| for i in range(n): | |||||
| print(f"Playing training game {i + 1}") | |||||
| game = Nim() | |||||
| # Keep track of last move made by either player | |||||
| last = { | |||||
| 0: {"state": None, "action": None}, | |||||
| 1: {"state": None, "action": None} | |||||
| } | |||||
| # Game loop | |||||
| while True: | |||||
| # Keep track of current state and action | |||||
| state = game.piles.copy() | |||||
| action = player.choose_action(game.piles) | |||||
| # Keep track of last state and action | |||||
| last[game.player]["state"] = state | |||||
| last[game.player]["action"] = action | |||||
| # Make move | |||||
| game.move(action) | |||||
| new_state = game.piles.copy() | |||||
| # When game is over, update Q values with rewards | |||||
| if game.winner is not None: | |||||
| player.update(state, action, new_state, -1) | |||||
| player.update( | |||||
| last[game.player]["state"], | |||||
| last[game.player]["action"], | |||||
| new_state, | |||||
| 1 | |||||
| ) | |||||
| break | |||||
| # If game is continuing, no rewards yet | |||||
| elif last[game.player]["state"] is not None: | |||||
| player.update( | |||||
| last[game.player]["state"], | |||||
| last[game.player]["action"], | |||||
| new_state, | |||||
| 0 | |||||
| ) | |||||
| print("Done training") | |||||
| # Return the trained AI | |||||
| return player | |||||
| def play(ai, human_player=None): | |||||
| """ | |||||
| Play human game against the AI. | |||||
| `human_player` can be set to 0 or 1 to specify whether | |||||
| human player moves first or second. | |||||
| """ | |||||
| # If no player order set, choose human's order randomly | |||||
| if human_player is None: | |||||
| human_player = random.randint(0, 1) | |||||
| # Create new game | |||||
| game = Nim() | |||||
| # Game loop | |||||
| while True: | |||||
| # Print contents of piles | |||||
| print() | |||||
| print("Piles:") | |||||
| for i, pile in enumerate(game.piles): | |||||
| print(f"Pile {i}: {pile}") | |||||
| print() | |||||
| # Compute available actions | |||||
| available_actions = Nim.available_actions(game.piles) | |||||
| time.sleep(1) | |||||
| # Let human make a move | |||||
| if game.player == human_player: | |||||
| print("Your Turn") | |||||
| while True: | |||||
| pile = int(input("Choose Pile: ")) | |||||
| count = int(input("Choose Count: ")) | |||||
| if (pile, count) in available_actions: | |||||
| break | |||||
| print("Invalid move, try again.") | |||||
| # Have AI make a move | |||||
| else: | |||||
| print("AI's Turn") | |||||
| pile, count = ai.choose_action(game.piles, epsilon=False) | |||||
| print(f"AI chose to take {count} from pile {pile}.") | |||||
| # Make move | |||||
| game.move((pile, count)) | |||||
| # Check for winner | |||||
| if game.winner is not None: | |||||
| print() | |||||
| print("GAME OVER") | |||||
| winner = "Human" if game.winner == human_player else "AI" | |||||
| print(f"Winner is {winner}") | |||||
| return | |||||
+ 4
- 0
nim/play.py
View File
| @ -0,0 +1,4 @@ | |||||
| from nim import train, play | |||||
| ai = train(10000) | |||||
| play(ai) | |||||
+ 8
- 0
pagerank/.idea/.gitignore
View File
| @ -0,0 +1,8 @@ | |||||
| # Default ignored files | |||||
| /shelf/ | |||||
| /workspace.xml | |||||
| # Datasource local storage ignored files | |||||
| /dataSources/ | |||||
| /dataSources.local.xml | |||||
| # Editor-based HTTP Client requests | |||||
| /httpRequests/ | |||||
+ 8
- 0
pagerank/.idea/dictionaries/yigit.xml
View File
| @ -0,0 +1,8 @@ | |||||
| <component name="ProjectDictionaryState"> | |||||
| <dictionary name="yigit"> | |||||
| <words> | |||||
| <w>pagerank</w> | |||||
| <w>pageranks</w> | |||||
| </words> | |||||
| </dictionary> | |||||
| </component> | |||||
+ 9
- 0
pagerank/.idea/misc.xml
View File
| @ -0,0 +1,9 @@ | |||||
| <?xml version="1.0" encoding="UTF-8"?> | |||||
| <project version="4"> | |||||
| <component name="JavaScriptSettings"> | |||||
| <option name="languageLevel" value="ES6" /> | |||||
| </component> | |||||
| <component name="ProjectRootManager" version="2" languageLevel="JDK_11" default="false" project-jdk-name="Python 3.8" project-jdk-type="Python SDK"> | |||||
| <output url="file://$PROJECT_DIR$/out" /> | |||||
| </component> | |||||
| </project> | |||||
+ 8
- 0
pagerank/.idea/modules.xml
View File
| @ -0,0 +1,8 @@ | |||||
| <?xml version="1.0" encoding="UTF-8"?> | |||||
| <project version="4"> | |||||
| <component name="ProjectModuleManager"> | |||||
| <modules> | |||||
| <module fileurl="file://$PROJECT_DIR$/.idea/pagerank.iml" filepath="$PROJECT_DIR$/.idea/pagerank.iml" /> | |||||
| </modules> | |||||
| </component> | |||||
| </project> | |||||
+ 6
- 0
pagerank/.idea/other.xml
View File
| @ -0,0 +1,6 @@ | |||||
| <?xml version="1.0" encoding="UTF-8"?> | |||||
| <project version="4"> | |||||
| <component name="PySciProjectComponent"> | |||||
| <option name="PY_SCI_VIEW_SUGGESTED" value="true" /> | |||||
| </component> | |||||
| </project> | |||||
+ 9
- 0
pagerank/.idea/pagerank.iml
View File
| @ -0,0 +1,9 @@ | |||||
| <?xml version="1.0" encoding="UTF-8"?> | |||||
| <module type="JAVA_MODULE" version="4"> | |||||
| <component name="NewModuleRootManager" inherit-compiler-output="true"> | |||||
| <exclude-output /> | |||||
| <content url="file://$MODULE_DIR$" /> | |||||
| <orderEntry type="inheritedJdk" /> | |||||
| <orderEntry type="sourceFolder" forTests="false" /> | |||||
| </component> | |||||
| </module> | |||||
+ 14
- 0
pagerank/corpus0/1.html
View File
| @ -0,0 +1,14 @@ | |||||
| <!DOCTYPE html> | |||||
| <html lang="en"> | |||||
| <head> | |||||
| <title>1</title> | |||||
| </head> | |||||
| <body> | |||||
| <h1>1</h1> | |||||
| <div>Links:</div> | |||||
| <ul> | |||||
| <li><a href="2.html">2</a></li> | |||||
| </ul> | |||||
| </body> | |||||
| </html> | |||||
+ 15
- 0
pagerank/corpus0/2.html
View File
| @ -0,0 +1,15 @@ | |||||
| <!DOCTYPE html> | |||||
| <html lang="en"> | |||||
| <head> | |||||
| <title>2</title> | |||||
| </head> | |||||
| <body> | |||||
| <h1>2</h1> | |||||
| <div>Links:</div> | |||||
| <ul> | |||||
| <li><a href="1.html">1</a></li> | |||||
| <li><a href="3.html">3</a></li> | |||||
| </ul> | |||||
| </body> | |||||
| </html> | |||||
+ 15
- 0
pagerank/corpus0/3.html
View File
| @ -0,0 +1,15 @@ | |||||
| <!DOCTYPE html> | |||||
| <html lang="en"> | |||||
| <head> | |||||
| <title>3</title> | |||||
| </head> | |||||
| <body> | |||||
| <h1>3</h1> | |||||
| <div>Links:</div> | |||||
| <ul> | |||||
| <li><a href="2.html">2</a></li> | |||||
| <li><a href="4.html">4</a></li> | |||||
| </ul> | |||||
| </body> | |||||
| </html> | |||||
+ 14
- 0
pagerank/corpus0/4.html
View File
| @ -0,0 +1,14 @@ | |||||
| <!DOCTYPE html> | |||||
| <html lang="en"> | |||||
| <head> | |||||
| <title>4</title> | |||||
| </head> | |||||
| <body> | |||||
| <h1>4</h1> | |||||
| <div>Links:</div> | |||||
| <ul> | |||||
| <li><a href="2.html">2</a></li> | |||||
| </ul> | |||||
| </body> | |||||
| </html> | |||||
+ 14
- 0
pagerank/corpus1/bfs.html
View File
| @ -0,0 +1,14 @@ | |||||
| <!DOCTYPE html> | |||||
| <html lang="en"> | |||||
| <head> | |||||
| <title>BFS</title> | |||||
| </head> | |||||
| <body> | |||||
| <h1>BFS</h1> | |||||
| <div>Links:</div> | |||||
| <ul> | |||||
| <li><a href="search.html">Search</a></li> | |||||
| </ul> | |||||
| </body> | |||||
| </html> | |||||
+ 15
- 0
pagerank/corpus1/dfs.html
View File
| @ -0,0 +1,15 @@ | |||||
| <!DOCTYPE html> | |||||
| <html lang="en"> | |||||
| <head> | |||||
| <title>DFS</title> | |||||
| </head> | |||||
| <body> | |||||
| <h1>DFS</h1> | |||||
| <div>Links:</div> | |||||
| <ul> | |||||
| <li><a href="bfs.html">BFS</a></li> | |||||
| <li><a href="search.html">Search</a></li> | |||||
| </ul> | |||||
| </body> | |||||
| </html> | |||||
+ 15
- 0
pagerank/corpus1/games.html
View File
| @ -0,0 +1,15 @@ | |||||
| <!DOCTYPE html> | |||||
| <html lang="en"> | |||||
| <head> | |||||
| <title>Games</title> | |||||
| </head> | |||||
| <body> | |||||
| <h1>Games</h1> | |||||
| <div>Links:</div> | |||||
| <ul> | |||||
| <li><a href="tictactoe.html">TicTacToe</a></li> | |||||
| <li><a href="minesweeper.html">Minesweeper</a></li> | |||||
| </ul> | |||||
| </body> | |||||
| </html> | |||||